




Wer hätte gedacht, dass ausgerechnet ein deutsches KI-Start-up beim Thema Datenschutz die Konkurrenz aus den USA und China rechts überholt? Die Geschichte, die Robin Ochs, CEO von Picture Instruments, aufdeckte, liest sich wie ein Lehrstück über Selbstbild und Wirklichkeit im digitalen Deutschland.
Schon seit Jahren pflegen wir in Deutschland ein gewisses Selbstbewusstsein, wenn es um Datenschutz geht. Während man in Foren und auf Messen gern über die „Datenkraken“ aus Übersee lästert, gilt das eigene Land als Bollwerk gegen den allzu sorglosen Umgang mit persönlichen Informationen. Doch die Realität ist, wie so oft, vielschichtiger. Und manchmal auch ironisch.
Robin Ochs wurde auf das Thema aufmerksam, weil ein Kunde seiner Software AI Lab nachfragte, wie es um die Trainingsdatennutzung der FLUX-Modelle von Black Forest Labs (BFL) steht. Was Ochs bei seiner Recherche zutage förderte, dürfte nicht nur Datenschützer, sondern auch professionelle Bildbearbeiter und Fotografen aufhorchen lassen: Die Nutzungsbedingungen der FLUX API sind in puncto Datenverwertung so weit gefasst, dass selbst Google und OpenAI im Vergleich fast zurückhaltend wirken.
Die Lizenz zum Trainieren – und zwar für immer
Im Zentrum der Debatte steht Abschnitt 2.(b) der FLUX API Service Terms von Black Forest Labs. Dort heißt es unmissverständlich:
„You grant us a fully paid, royalty-free, perpetual, irrevocable, worldwide, non-exclusive and fully sublicensable right and license to use, sub-license, distribute, reproduce, modify, adapt, publicly perform, and publicly display your Input and Output for the purpose of operating the FLUX Services, improving our products and services, and developing new products and services.
You acknowledge the foregoing means we may use Inputs and Outputs to train and improve our artificial intelligence models, algorithms, and related technology, products, and services.“
(Quelle: https://bfl.ai/legal/flux-api-service-terms)
Eine Einschränkung oder gar ein Opt-out? Fehlanzeige. Wer FLUX nutzt, räumt BFL ein weltweites, unwiderrufliches und dauerhaftes Nutzungsrecht an sämtlichen Eingaben und Ausgaben ein. Ausdrücklich auch zur Verbesserung und zum Training der eigenen KI-Modelle. Das ist nicht nur ungewöhnlich offen formuliert, sondern auch in seiner Reichweite bemerkenswert.
Die Konkurrenz: Zurückhaltung mit Fußnoten
Zum Vergleich lohnt ein Blick auf die großen Namen der Branche. Google etwa betont in den Nutzungsbedingungen für die Gemini API ausdrücklich, dass bei kostenpflichtigen Diensten keine Nutzerdaten, und dazu zählen ausdrücklich auch Bilder, zur Verbesserung der Produkte verwendet werden:
„when you use Paid Services, Google does not use your prompts (including associated system instructions, cached content, and files such as images, videos, or documents) or responses to improve our products…“
(Quelle: https://ai.google.dev/gemini-api/docs/zdr)
OpenAI wiederum stellt gleich zu Beginn klar:
„Your data is your data. (…) As of March 1, 2023, data sent to the OpenAI API is not used to train or improve OpenAI models (unless you explicitly opt in to share data with us).“
(Quelle: https://platform.openai.com/docs/guides/your-data)
Selbst bei BytePlus, dem internationalen KI-Ableger von Bytedance, finden sich laut den vorliegenden Nutzungsbedingungen Hinweise darauf, dass Nutzereingaben nicht ohne Weiteres zum Training der Basismodelle verwendet werden sollen, auch wenn sich die genaue Formulierung im aktuellen Dokument nicht eindeutig verifizieren lässt.
Ironie des Standorts: Datenschutz made in Germany?
Geradezu paradox mutet es an, dass ausgerechnet ein deutsches Unternehmen, das sich als europäische Alternative zu den Tech-Giganten positioniert, beim Thema Trainingsdaten die großzügigste Auslegung wählt. Während Google und OpenAI zumindest für ihre API-Kunden klare Grenzen ziehen und explizite Opt-in-Mechanismen vorsehen, setzt Black Forest Labs auf ein umfassendes, nicht widerrufbares Nutzungsrecht. Und das ohne jede Einschränkung.
Für Anwender, die mit sensiblen Bilddaten arbeiten, ist das mehr als eine Fußnote. Es ist ein handfester Grund, die FLUX-Modelle mit Vorsicht zu genießen. Robin Ochs zieht für AI Lab die Konsequenz: Künftig werden die FLUX-Modelle dort standardmäßig ausgeblendet. Wer sie nutzen will, muss ein Häkchen setzen und eine deutliche Warnung bestätigen. Ein Schritt, der Transparenz schafft, aber auch die Frage aufwirft, wie viel vom deutschen Datenschutz-Mythos im Alltag tatsächlich übrig bleibt.
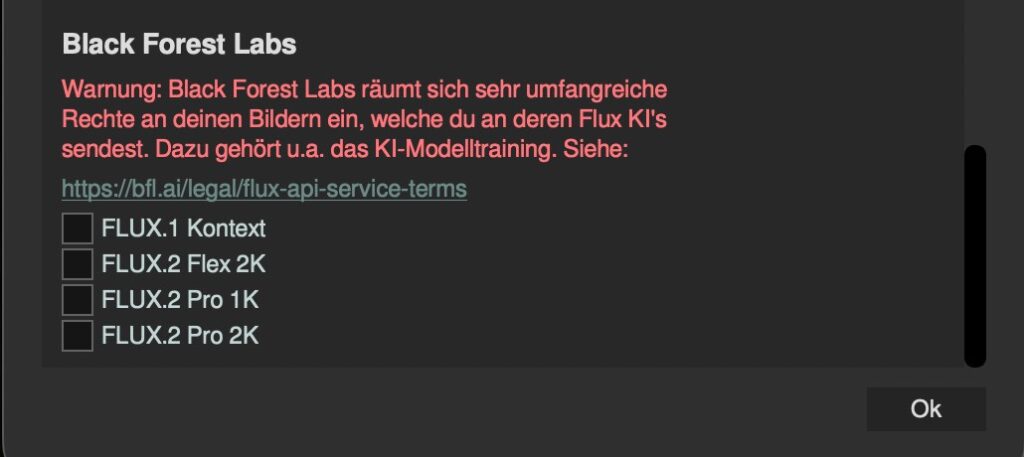
Zwischen Anspruch und Wirklichkeit
Die Geschichte zeigt, wie groß die Kluft zwischen Selbstbild und Realität im Umgang mit KI und Trainingsdaten geworden ist. Während der Ruf nach europäischen Alternativen zu den US- und China-Modellen laut bleibt, sind es am Ende vielleicht auch die heimischen Anbieter, die beim Thema Datenverwertung am wenigsten Zurückhaltung zeigen. Für Profis, die mit sensiblen Bilddaten arbeiten, bleibt nur, ganz genau hinzusehen. Im Zweifel sollte man also lieber einmal mehr auf das Kleingedruckte zu achten.

Alarmismus? Streit um des Kaisers Bart? Clickbaiting?
Hohe Datenschutzanforderungen stellen klar, dass keine Daten unerlaubt und ungefragt, also heimlich genutzt werden sollen. Ganz genau diese Anforderung erfüllt das genannte Unternehmen geradezu vorbildlich: Es informiert klar und unmissverständlich, was es mit den Daten machen wird. Der Nutzer bestätigt das durch seine Teilnahme und/oder Nutzung. Anm.: Ich habe hier nicht geprüft, ob er sogar explizit per Häkchen/Klick bestätigt, dass er das gelesen hat.
Oma hat schon gemahnt: „Unterschreib nichts, was du nicht gelesen hast!“ – und jeder Jurist wird das bestätigen.
So gesehen, ist der Artikel Donner ohne Blitz, Rauch ohne Feuer … und hat einen einzigen (halb)sinnvollen Satz: „Im Zweifel sollte man also lieber einmal mehr auf das Kleingedruckte zu achten.“
„Für Profis, die mit sensiblen Bilddaten arbeiten, bleibt nur, ganz genau hinzusehen.“ Und weshalb eigentlich soll das nur für Profis gelten – für „Nichtprofis“ ist Datenschutz und „Kleingedrucktes lesen“ also vollkommen unwichtig? Interessante Sichtweise …
„Die Geschichte zeigt, wie groß die Kluft zwischen Selbstbild und Realität im Umgang mit KI und Trainingsdaten geworden ist.“
Nein, diese Geschichte hier zeigt nur eins: Wie wichtig es ist, das „Kleingedruckte“ zu lesen (und zu verstehen) – Stichworte „Medienkompetenz“ und „Mündigkeit“.
„Während der Ruf nach europäischen Alternativen zu den US- und China-Modellen laut bleibt, sind es am Ende vielleicht auch die heimischen Anbieter, die beim Thema Datenverwertung am wenigsten Zurückhaltung zeigen.“
Nein, es sind am Ende „die heimischen Anbieter“, die offen und ehrlich darlegen, was sie tun – Stichwort „Transparenz“. Macht einer Transparenz real, ist es nun auch wieder nicht recht?
Kein Kunde wird gezwungen, das betreffende Produkt zu nutzen – im Zweifel wird sogar noch dafür bezahlt, freiwillig.