



Daten komprimieren – so viele Bits sind gar nicht nötig
Dass die Dateikomprimierung eine Geschichte voller Missverständnisse ist, musste ich hier erst kürzlich wieder erfahren. Gehen wir das Thema also mal ganz grundsätzlich an …
Es gibt Daten und es gibt die Datenträger, auf denen sie gespeichert werden, und zumindest früher war es so, dass der Speicherplatz für die Daten schnell knapp wurde. Man musste die sich im Laufe der täglichen Computernutzung ansammelnden Datenmassen daher irgendwie komprimieren. Die Wahl eines geeigneten Kompressionsverfahrens wurde zunächst meist durch die Randbedingung verschärft, dass es verlustfrei sein sollte: Aus den reduzierten Daten mussten sich die Originaldateien eins zu eins wiederherstellen lassen. Ein Programm, dessen Code durch eine Komprimierung auch nur ein Bit verloren ginge, würde vermutlich nicht mehr fehlerfrei laufen, und wenn Buchhaltungsdaten nicht mehr ganz stimmig wären, könnte es spätestens bei einer Steuerprüfung Ungemach geben. Wie aber ließen sich dieselben Informationen mit weniger Daten speichern?

Der wichtigste Ansatz dazu beruht auf der Reduzierung von Redundanz: Nicht alles in einer Datei ist völlig neu; manches wiederholt bloß etwas, das bereits an anderer Stelle vorkam. Wenn man auf eine solche Wiederholung stößt, braucht man nicht alle Daten erneut abzuspeichern; ein Verweis auf das erste Vorkommen reicht. (Informatiker, die bekanntlich ein bisschen anders als gewöhnliche Menschen denken, erklären sich den Aufbau populärer Songs eben mit deren Redundanz: Wenn jede Strophe auf dieselbe Melodie gesungen wird, muss man sich nicht so viele Noten merken, und wenn jede Strophe denselben Refrain hat, wiederholt sich auch der Text – ideales Ohrwurmmaterial, das im Gehirn von Sänger wie Publikum nur wenig Speicherplatz erfordert. Der Informatikpapst Donald E. Knuth hat dies 1977 in The Complexity of Songs analysiert und den Speicherbedarf diverser typischer Songs in Formeln gefasst. Ob seine Vermutung zutrifft, dass „the advent of modern drugs has led to demands for still less memory space“, ist auch unter Informatikern umstritten.)
Wie auch immer: Je mehr sich Inhalte wiederholen, desto mehr Platz lässt sich durch eine Eliminierung der Redundanz sparen. Oft muss man die Daten dazu zunächst in eine für die Komprimierung ideale Form transformieren, in der die Wiederholungen erst offensichtlich werden. Manchmal gibt es auch eine Selbstähnlichkeit in den Daten, wenn sich nämlich grobe und feine Strukturen gleichen: Ein und dasselbe Muster kehrt in verschiedenen Maßstäben wieder.
Eine Eliminierung von Redundanz ist selbst dann noch möglich, wenn sich die Vorkommen nicht exakt gleichen – es genügt, wenn die Unterschiede gering sind. Dabei hilft ein zweites wichtiges Grundprinzip der Datenreduktion, nämlich eine Entropiekodierung. Man zerlegt den Inhalt einer Datei in einzelne Symbole, die jeweils eine eigene Bitfolge als Code erhalten. Die Buchstaben eines Textes beispielsweise werden normalerweise in den jeweils sieben Bit des ASCII-Codes kodiert oder – inklusive der Umlaute und „ß“ – in den acht Bit von Latin-1 – jedem Zeichen entspricht eine gleich lange Folge von Bits. Für deren weitere Verarbeitung ist das bequem, aber wenn man die Zahl der Bits pro Zeichen variabel hält, lässt sich Platz sparen, indem man die am häufigsten vorkommenden Buchstaben mit den wenigsten Bit speichert. Dieses Prinzip lag schon dem Morse-Code zugrunde, der dem im Englischen (und zufällig auch im Deutschen) häufigsten Buchstaben „e“ den kürzesten Code „・“ zuordnete. Auch reine Zahlenwerte haben durchweg unterschiedliche Häufigkeiten – kleine Zahlen sind meist häufiger als große –, und dies lässt sich ausnutzen, indem man die in einer Datei vorkommenden Zahlen zunächst nach der Häufigkeit ihres Auftretens sortiert und ihnen dann in dieser Reihenfolge Codes von den kürzesten bis zu den längsten Bitfolgen zuordnet. Wenn eine bestimmte Sequenz von Daten nicht genau, aber wenigstens ungefähr wiederkehrt, braucht man nur die Differenz neu zu speichern. Diese enthält kleinere, häufiger vorkommende Zahlen, die sich mit weniger Bits speichern lassen.
Mit verlustfreien Kompressionsverfahren auf der Basis von Redundanzeliminierung und Entropiekodierung kann man die Zahl der nötigen Bits, abhängig vom Inhalt, oft auf die Hälfte reduzieren und manchmal auf ein Viertel. Im ungünstigsten Fall – etwa einer Folge von Zufallszahlen – sind die Daten allerdings gar nicht komprimierbar.
Seit den 1980er Jahren hatte man es immer öfter mit Bilddaten zu tun, erst rein schwarzweißen, dann Graustufenbildern und schließlich solchen mit Millionen Farben und mehr. Und deren Auflösung wuchs. Galt in Megabyte zunächst noch als komfortabel großer Speicherplatz (auf eine Diskette, seinerzeit ein gängiges Massenspeichermedium, passten 0,36 bis 1,4 Megabyte), wuchs die täglich anfallende Datenmenge bald auf das Hundert- bis Tausendfache. Mit einer verlustfreien Komprimierung war da nur noch wenig auszurichten und die wachsende Informationsdichte der Speichermedien konnte das nur zum Teil auffangen. Bei den Medien, die vor allem so große Speicheranforderungen stellten, war eine verlustfreie Komprimierung aber auch gar nicht zwingend notwendig. Wenn man Bilder oder Töne digital speichert, sind die Bits nur ein Mittel zum Zweck. Es kommt nicht darauf an, die Originaldaten Bit für Bit identisch wiederherzustellen, denn so lange sich ein Bild nicht vom Original unterscheiden lässt, reicht das für alle praktischen Belange aus; die Komprimierung ist dann visuell beziehungsweise für unser Gehör verlustfrei. Nicht mehr die Mathematik gibt dann vor, wann eine komprimierte Datei dem Original entspricht, sondern unsere Sinnesphysiologie, für die manche Unterschiede in den Daten keinen Unterschied in der Wahrnehmung machen.
Solche Kriterien liegen dem JPEG-Kompressionsverfahren für Bilder wie auch dem MP3-Verfahren für Audiodateien zugrunde, und ebenso deren aktuelle Weiterentwicklungen. Mit solchen verlustbehafteten Verfahren ist eine Datenreduzierung auf rund ein Zehntel und manchmal mehr möglich, ohne dass Auge, Ohr und Gehirn einen Verlust bemerken. Die Grundlage einer verlustbehafteten Komprimierung bilden immer noch eine Eliminierung von Redundanz und eine Entropiekodierung, aber zusätzlich werden Informationen entfernt oder vergröbert, deren Fehlen uns nicht auffällt. Die Komprimierung von Raw-Dateien ist dabei besonders herausfordernd, da man einerseits eine starke Datenreduzierung anstrebt, andererseits aber das Potential der Rohdaten für eine weitere Bildbearbeitung nicht schmälern möchte. Oft beschränkt man sich daher auf eine verlustfreie Komprimierung von Raw-Daten, aber mittlerweile existieren auch verlustbehaftete und daher noch effektivere Verfahren, die sich bedenkenlos einsetzen lassen, wenn der Speicherplatz knapp ist. Minimale Verluste an kaum bemerkbaren Bilddetails sind eher zu verschmerzen als ein Foto, das man gar nicht erst aufnehmen konnte, weil die Speicherkarte voll war.

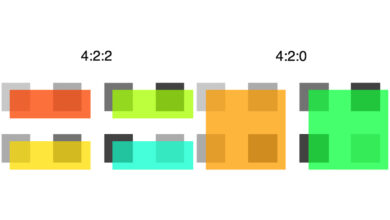


… hatte man es immer öfter mit Bilddaten zu tun, erst … schließlich solchen mit Millionen Farben und mehr.
Da hat der Informatiker den Werbe-Sprech übernommen – tatsächlich sind es ein paar weniger Farben – bei RGB genau deren drei: Rot, Grün und Blau.
Genauso viele Grundfarben, wie sie unsere eigenen Augen unterscheiden, um damit Millionen verschiedener Farbtöne differenzieren zu können.
Die im menschlichen Gehirn stattfindende Differenzierung ist hier vollkommen nebensächlich – es geht ausschließlich um die Möglichkeit von Geräten, Farben darstellen zu können. Und das sind bei RGB-Geräten niemals mehr als deren drei. Selbst dann nicht, wenn man mehr zu sehen glaubt.
.
Aus Blau und Rot kann das menschliche Gehirn die Wahrnehmung der Farbe Lila haben, auch wenn diese Farbe tatsächlich nicht vorhanden ist. Es scheint, als ob viel mehr als die drei Grundfarben entstünden. Jedoch passiert das bei der Signalverarbeitung im Gehirn (in der menschlichen Wahrnehmung), nicht in den technischen Ausgabegeräten.
.
Richtig ist, dass für Ausgabegeräte (Bildschirme) die drei Grundfarben mit je 256 Helligkeitsstufen zu Farbtönen kombiniert werden. Also 256 Rottöne + 256 Grüntöne + 256 Blautöne; folglich maximal 768 verschiedene Farbtöne, niemals jedoch Millionen von Farben.
.
Der Mensch ist bekanntlich zu beachtlichen Leistungen fähig. Jedoch scheitern die meisten schon daran, 256 Helligkeitsstufen ohne Hilfsmittel unterscheiden zu können. Deshalb ist es schlicht aberwitzig zu glauben, der Mensch könne die mathematisch möglichen Kombinationen von 256 * 256 * 256 Farbtönen auch nur annähernd unterscheiden. Letzteres ist wiederum der hauptsächliche Grund, weshalb es keine Bildschirme gibt, die mehr als 8-Bit pro Farbe ausgeben. Unbenommen davon, dass in der Bildbearbeitung mit größeren Bit-Tiefen gerechnet wird.
.
Von Millionen Farben zu sprechen ist insofern sowohl in technischer Hinsicht als auch hinsichtlich menschlicher Wahrnehmung schlicht Irrglaube, der vermeintlich mit mathematischen Berechnungen bewiesen werden könne. Oder eben Werbes-Sprech, mit dem das Kaufverhalten beeinflusst werden soll.
Darüber, was nebensächlich ist, scheiden sich offenbar die Geister …
Ich schrieb hier von der technischen Entwicklung der 1980er und 90er Jahre. In den späten 80ern war schon froh, wer eine 8-Bit-Grafikkarte hatte, mit der sich 256 Farben unterscheiden ließen. Immerhin konnte man selbst bestimmen, welche 256 Farben das sein sollten. Wenn man die verwendete Palette für jedes einzelne Bild optimierte – es gab Software, die einen dabei unterstützte –, konnte man mit etwas Glück hässliche Farbabrisse vermeiden, aber oft blieb man auf die kompromisslerische Systempalette angewiesen. Mit 16 Bits und „Tausenden von Farben“ – genauer gesagt den 32.768 Farben, die sich mit fünf Bits pro RGB-Kanal darstellen ließen –, war man schon besser dran, aber der Goldstandard waren 24 Bits, mithin acht Bits pro Kanal und damit 16.777.216 Farben. Schon Apples QuickTake 150 von 1997 hatte zwar nur 0,3 Megapixel, aber eine 24-Bit-Farbauflösung; mit deren Millionen von Farben war man seinerzeit ganz weit vorne. Ich bin allerdings erst in die Digitalfotografie eingestiegen, als Olympus kurze Zeit später verschwenderische 0,8 Megapixel mit Millionen von Farben bot. Für so um die 1800 DM.
Mit 768 Farben dürfte man z.B. wohl kaum einen glatten Himmelsverlauf ohne Abrisse darstelen können.
Es ist eher eine Frage der Optik und der Auflösung des menschlichen Sehapparates – wir sehen ja nicht RGB-Punkte unterschiedlicher Intensität am Monitor, sondern bei normalem Monotor-Betrachtungsabstand die sich ergebenden (Misch)Farben. Wie viele das sind, hängt auch sehr von individuellen Faktoren ab. Wollte man das trennscharf definieren, düfte man aus roter und gelber Ölfarbe angemischte Farben unterschiedlicher Intensität auch nur als zwei Farben bezeichnen, weil man bei starker Vergrößerung nur rote und gelbe Pigmente sähe. Orange und Übergangstöne gäbe es dann gar nicht. Das kann man zwar machen, mit der Praxis der Wahrnehung hätte das aber wenig zu tun.
Es ist traurig und beschämend wenn im Blog einer vorgebliche Fachzeitschrift immer wieder hervorgehoben wird, wie schlechtere Ergebnisse als hinreichend oder besonders gut und empfehlenswert gepriesen werden.
Fakt ist, dass man seit der Wiedergabe der Wirklichkeit durch Kratzer in Felsen im Lauf der Jahrtausende einige Fortschritte erzielt hat. Doch soll man nie verschweigen, dass es sich immer um subjektiv gewählte Ausschnitte und ebenso subjektiv gewählte Darstellungen der Wirklichkeit sind. Deshalb fand ich den Blog über das „fehlende Fensterglas“ in einem Gemälde mehr als skurril. Zeichner und Maler hatten immer alle Freiheiten!
Dass jedes Foto und jeder Film oder jedes Video ein schlappes oder aufgemotztes Abbild der Wirklichkeit ist, sollte immer hervorgehoben werden.
Wären datenreduzierte Formate richtig schlecht, würde sie kaum jemand nutzen, sie wären ohne Erfolg. Und die Evolution lehrt uns ja, dass erfolglose Erfindungen nicht überlebensfähig sind. Ist ja trivial.
Deswegen haben datenreduzierte Formate bei Bild und Video ihre Berechtigung. Allerdings, und das fehlt in vielen dieser Beiträge, vor allem für das ausgearbeitete Endprodukt. Und dann, wenn es auf mehr oder weniger für alle Ewigkeit verlorene Informationsdaten nicht ankommt, was meist der Fall ist, in Museen ist bekannt, dass die durchschnittliche Ansichtsdauer eines Ausstellungsstücks von Besuchern etwa 4 Sekunden beträgt. Wie lange wird das für ein Bild auf einer Website oder einer Zeitschrift sein?
Allerdings versagen datenreduzierte Bilder jeden Nutzen, wenn das Bild weiter bearbeitet werden soll. Nicht nur wegen der bei der Nutzung unbedingt nötigen Erfindung von fehlenden Pixeln, sondern auch weil JPG keine für die Weiterbearbeitung meist nötigen Farbtiefe besitzen. Darauf wird IMO kaum bis nie in populären Fachzeitschriften hingewiesen.
Und abschließend muss auch noch hingewiesen werden, dass allein durch die Technik der Aufnahme, egal ob analog oder digital, schon der erste sehr große Qualitätsverlust der Wirklichkeit entsteht. Der Wirklichkeit, wie wir sie mit den für das Überleben entwickelten Sinnen des Lebewesens wahrnehmen können.