



Farbunterabtastung: 4:2:0 … Wer bietet mehr?
Wenn es um die Qualität von JPEG-Dateien und Videos geht, werden oft kryptische Zahlenkombinationen wie 4:4:4, 4:2:2 und 4:2:0 verwendet. Diese mit dem Begriff Farbunterabtastung beziehungsweise Chroma Subsampling zu erklären, hilft auch nicht unbedingt weiter. Wofür stehen die Zahlen?
Bilder, ob Stand- oder Videobilder, sind schön, brauchen aber viel Platz. Deshalb versucht man, Bilddaten vor der Speicherung zu komprimieren – auf eine Weise, in der möglichst viele Daten wegfallen, die für einen menschlichen Betrachter wichtigsten Informationen aber erhalten bleiben. Ein Ansatz, den fast alle Komprimierungsverfahren nutzen, beruht darauf, dass wir Farbinformationen schlechter als Helligkeitsinformationen auflösen. Das hat wohlgemerkt nichts damit zu tun, dass es unter den Sinneszellen unserer Augen fünf mal mehr für Helligkeiten empfindliche Stäbchen als farbempfindliche Zapfen gibt. In der Sehgrube, in der wir am schärfsten sehen, gibt es nämlich nur Zapfen, während die Stäbchen in der Peripherie dominieren. Die geringere Auflösung für Farben ergibt sich vielmehr erst in der weiteren Verarbeitung im Gehirn.
Um diesen Umstand auszunutzen, indem man Farben mit geringerer Auflösung als Helligkeiten speichert, ist das RGB-Farbmodell leider ungeeignet. Der Rotkanal beispielsweise sagt uns einerseits, welchen Anteil Rot an einer Farbe hat, trägt aber auch ein Drittel zur Gesamthelligkeit bei. Entsprechendes gilt für den Grün- und Blaukanal. Farb- und Helligkeitsinformationen sind nicht voneinander getrennt, und deshalb rechnet man Bilder für Verfahren wie die JPEG-Kompression erst einmal vom RGB- in das YCrCb-Modell um. Dessen Y-Kanal enthält nur die Helligkeit, also den Durchschnitt der Helligkeiten im Rot-, Grün- und Blaukanal. Im Cr-Kanal speichert man die Abweichung des Rotkanals von der Durchschnittshelligkeit und im Cb-Kanal die Abweichung des Blaukanals. Der Wert für den Grünkanal lässt sich daraus berechnen und braucht nicht eigens gespeichert zu werden. Damit sind die Komponenten Helligkeit (Y) und Farbigkeit (Cr und Cb) voneinander getrennt und man kann daran gehen, die Farbdaten mit verringerter Auflösung zu speichern. Das bezeichnet man als Farbunterabtastung oder englisch als Chroma Subsampling. Dieser Kniff wurde übrigens schon in der analogen Ära genutzt, etwa beim Farbfernsehstandard PAL.
Wie die Farbunterabtastung bei digitalen Komprimierungsverfahren konkret erfolgt, lässt sich durch drei Zahlen beschreiben. Dazu betrachtet man exemplarisch zwei Zeilen von je vier Bildpixeln, also insgesamt acht Pixel. Die erste Zahl gibt an, wie viele Helligkeitsinformationen für die vier Pixel einer Zeile gespeichert werden. Diese Zahl ist immer gleich 4, denn wäre sie geringer, würden wir die Bildauflösung insgesamt verringern; das wäre aber ein Herunterskalieren und keine Komprimierung – ein ganz anderes Thema. Die zweite Zahl ist die Zahl der Farbinformationen, die für die Pixel der ersten Zeile gespeichert werden, und die dritte Zahl nennt diesen Wert für die zweite Zeile. Typische Kombinationen sind 4:4:4, 4:2:2 und 4:2:0, und das sieht dann so aus:

4:4:4 ist tatsächlich gar keine Farbunterabstastung, denn es werden alle Farbinformationen gespeichert. Zu den je vier Helligkeitsinformationen pro Zeile kommen ebenfalls je vier Farbinformationen. Das sind 8 Helligkeitswerte (Y) und 16 Farbwerte, denn für die Farbinformation müssen ja jeweils zwei Werte, Cr und Cb, gespeichert werden, insgesamt also 24 Werte.
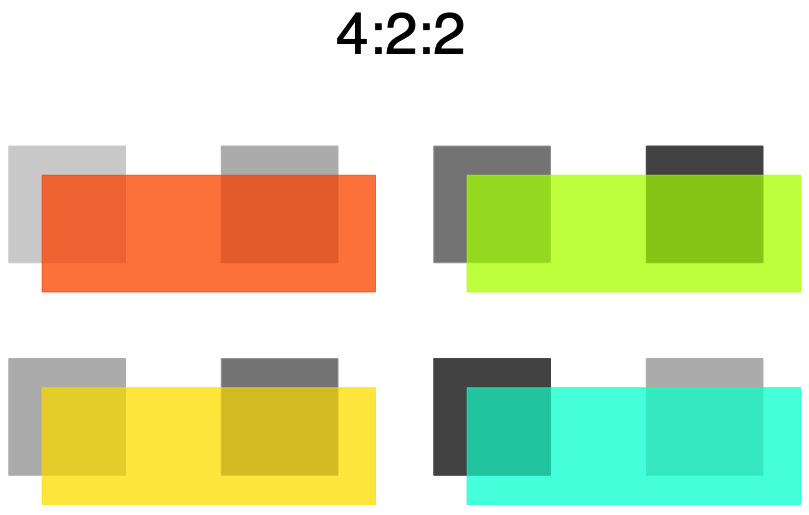
Bei einer Farbunterabtastung von 4:2:2 werden für je vier Pixel einer Zeile nur zwei Farbwerte gespeichert. Die Farbwerte zweier nebeneinander liegender Pixel müssen dazu gemittelt werden. Zu den 8 Helligkeitswerten kommen noch 8 (2 × 4) Farbwerte, insgesamt folglich 16. Gegenüber den 24 Werten ohne Farbunterabtastung haben wir ein Drittel eingespart.
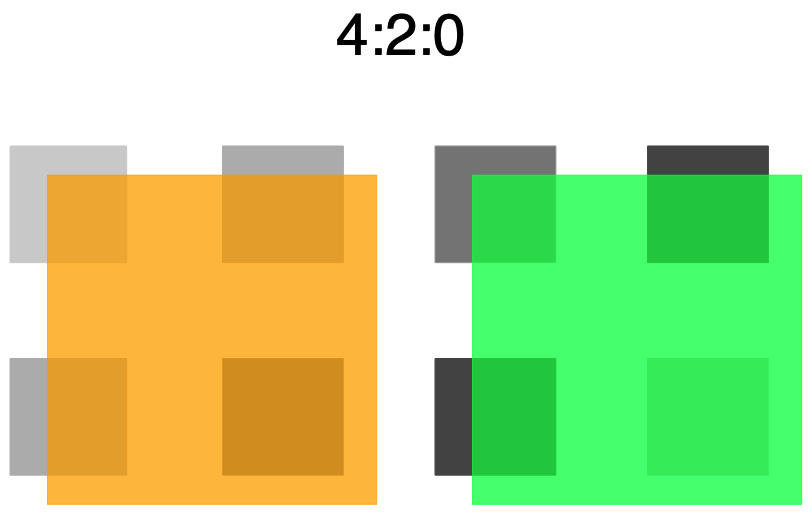
Die Farbunterabtastung 4:2:0 geht noch einen Schritt weiter: Für die zweite Pixelzeile werden gar keine Farbwerte gespeichert, so dass diese Pixel mit den Farbwerten der ersten Zeile versorgt werden müssen. Dazu werden die Farben von jeweils vier Pixeln gemittelt und dieser Mittelwert gespeichert. Neben den 8 Helligkeitswerten sind nur noch 4 (2 × 2) Farbwerte nötig, also insgesamt 12 Werte. Gegenüber den 24 Werten ohne Farbunterabtastung ist das eine Reduktion auf die Hälfte.
Andere Schemata als diese drei wären möglich, kommen aber seltener vor. 4:0:0 beispielsweise wäre ein reines Schwarzweißbild und 4:4:0 hätte ähnliche Eigenschaften wie 4:2:2, nur dass statt der Farbwerte zweier nebeneinander liegender Pixel die zweier untereinander liegender Pixel gemittelt würden.
Die so erreichte Datenreduktion reicht gewöhnlich noch nicht aus, weshalb sich weitere Komprimierungsschritte anschließen, bei JPEG etwa eine Diskrete Kosinustransformation und eine Entropiekodierung – aber das ist eine andere Geschichte und soll ein anderes Mal erzählt werden.
Man könnte sich nun fragen, warum man die Farbinformationen nicht grundsätzlich kräftig reduziert, etwa auf 4:2:0, wenn wir Farben doch ohnehin schlechter auflösen. Das ist auch richtig, so weit es den Schärfeeindruck betrifft. Wenn Sie ein Farbbild in Photoshop in das Lab-Modell umrechnen, das ähnlich wie YCrCb zwischen Helligkeits- und Farbinformationen unterscheidet, können Sie alternativ einmal den Helligkeitskanal und dann die Farbkanäle weichzeichnen: Die Version mit weichgezeichneten Farbkanälen und dem originalen Helligkeitskanal wirkt immer noch relativ scharf, während ein weichgezeichneter Helligkeitskanal trotz nach wie vor hochaufgelöster Farbkanäle ein unscharfes Bild ergibt.
Ein Problem mit der Farbunterabtastung ist aber bereits in den Illustrationen oben zu erahnen. Die Reduzierung der Farbinformationen erfordert, die Farben mehrerer Pixel zu mitteln, und dabei werden die Farben verfälscht. Aus Komplementärfarben wird eine unansehlich gräuliche Farbe und von einem roten Pixel in einem weißen oder schwarzen Umfeld bliebe nur eine kaum noch erkennbare ungesättigte Farbe übrig. Den Unterschied zum Original können wir dank der zahlreichen Zapfen in der Fovea centralis der Netzhaut sehr wohl erkennen.
Aus diesem Grund ist es durchaus eine Überlegung wert, auf eine allzu starke Farbunterabtastung zu verzichten. Was sie an Platzersparnis bringt, ist ohnehin geringer als das, was die folgenden Schritte erreichen. Gerade bei von vornherein niedrig aufgelösten Bildern für die Präsentation im Web ist es sinnvoll, die Farbauflösung zu erhalten, sofern das Bild feine, vor allem farblich kontrastierte Strukturen enthält. Leider gehen die sozialen Netze in dieser Hinsicht sehr grobschlächtig vor, wenn Bilder die ideale Auflösung übersteigen, und komprimieren dann ohne Rücksicht auf Verluste bei der Detailzeichnung.



Schade, wieder eine verpasste Gelegenheit!
Von einer Datenkompression kann man nur dann sprechen, wenn aus der komprimierten Datei die gesamte originale Information wieder hergestellt werden kann.
JPG bei Fotos ist eine datenvernichtende Kompression, mit der man das menschliche Hirn täuschen kann, die jedoch bei der Darstellung oder Bearbeitung eines einmal datenreduzierten Bilds niemals der tatsächliche Inhalt wieder hergestellt werden kann. Selbst bei der Einstellung der besten Qualität. Der Algorithmus, der aus dem datenreduzierten komprimierten Foto ein Bild errechnet, muss fehlende Informationen erfinden, interpolieren oder was auch immer. Es ist jedenfalls ein anderes Bild als das Original.
Es gibt auch für Bilder Dateiformate, die tatsächlich nur komprimieren, ähnlich wie eben auch Programme komprimiert gespeichert werden können. Jeder kennt gezippte Programmdateien. Würde man die nach mit Datenverlust komprimieren, könnte sie nach dem Entzippen nie funktionieren. Futsch ist futsch, sollte doch jedem klar sein.
Eine korrekte Ausdrucksweise wäre erforderlich.
Als Informatiker verwende ich die etablierte Fachterminologie … Es gibt verlustfreie Kompressionsverfahren, bei denen keine Informationen verloren gehen, und verlustbehaftete Kompressionsverfahren, für die das nicht gilt. Hier geht es – wie fast immer, wenn Stand- oder Videobilder komprimiert werden – um verlustbehaftete Kompressionsverfahren.
Es ist erfreulich, dass zumindest Sie keine Gelegenheit verpassen, und das ist doch auch schon mal ein verlässlicher Fixpunkt.
Komprimieren bedeutet zunächst nichts anderes als „zusammenpressen, verdichten“. Wenn Sie eine voluminöse Daunenweste in Ihren Koffer quetschen, nimmt deren Volumen erheblich ab. Wird sie nach dem Auspacken „dekomprimiert“, sind noch alle Daunen drin. Muss ich dagegen einen zu langen Text für einen Artikel auf zwei Seiten komprimieren, fehlen anschließend viele Wörter (und die kann man auch nicht mit Sicherheit rekonstruieren). Es gibt also sowohl umgangs- wie fachsprachlich unterschiedliche Bedeutungen dieses Begriffs (und anderer), und es wäre unangemessen, sich jeweils lediglich auf die eine Bedeutung zu beschränken, die Ihnen aus Ihrem Tätigkeitsfeld vertraut ist.
Ein weiteres Schema, vor allem für Bandbasierende Videoformate, ist 4:1:1, das für das NTSC-Digital-Video-Format (NTSC-DV) sowie für das DVCPro-Format von Panasonic verwendet wird, bzw. wurde. Im Gegensatz zu PAL-DV mit 4:2:0 werden hier stets vier benachbarte Pixel in einer Zeile farblich zusammengefasst. Die gesamte Farbauflösung entspricht dabei der Farbabtastung mit 4:2:0, jedoch mit höherer vertikaler Auflösung zuungunsten der horizontalen Auflösung. Bei Digital Betacam von Sony und DVCPro 50 von Panasonic kommt das 4:2:2-Abtastraster zum Einsatz.