


Die neuen KI-Bildgeneratoren wie Nono Banana, GPT Image-1 oder Seedream 4.0 vollziehen im Verborgenen eine tiefgreifende Revolution. Die neue Generation von Modellen kann nicht nur Bilder hervorbringen – sie komponiert Layouts, bearbeitet Fotos auf semantischer Ebene und entwirft Infografiken. Ein Blick auf die Technik, die den Beruf des Gestalters neu definieren wird.
Rückblick
Es ist ein faszinierendes Schauspiel, dem wir in den letzten Jahren beiwohnen durften: das digitale Werden von Bildern. Wir haben gelernt, die Magie der Diffusionsmodelle zu deuten, jenen schrittweisen Prozess, bei dem aus purem Rauschen, angeleitet durch unsere Worte, visuelle Welten entstehen. Midjourney, Stable Diffusion und ihre Verwandten wie Midjourney agieren wie digitale Fotochemiker, die ein latentes Bild langsam im Entwicklerbad sichtbar machen. Dieser Prozess hat eine beinahe meditative Qualität, doch er ist in seiner Essenz limitiert. Ein Diffusionsmodell ist ein hochspezialisierter Künstler für eine einzige Aufgabe: die Anfertigung eines finalen Bildes aus dem scheinbaren Nichts.
Diese Ära neigt sich nun ihrem Ende zu. Modelle wie Googles „Nano Banana“ (ein interner Spitzname für eine Weiterentwicklung der Gemini-Familie) oder Seedream 4.0 von ByteDance sind nicht einfach nur schnellere Versionen ihrer Vorgänger. Sie basieren auf einer fundamental anderen Architektur, die es ihnen erlaubt, weit über die reine Bildproduktion hinauszugehen. Sie markieren den Übergang von der digitalen Kamera zum voll ausgestatteten Designstudio.
Vom Maler zum intelligenten Layouter
Der entscheidende Unterschied liegt nicht in der Geschwindigkeit, sondern im Verständnis. Während ein Diffusionsmodell eine Textbeschreibung in ein Meer von Pixeln übersetzt, arbeiten die neuen Modelle mit einem integrierten, multimodalen Verständnis von Raum, Objekten und sogar Typografie. Sie sehen ein Bild nicht als flache Matrix, sondern als eine Komposition aus semantischen Einheiten: Hier ein Gesicht, dort ein Baum, dazwischen ein Textblock.
Diese Fähigkeit ist das direkte Resultat ihrer Architektur. Anstelle eines schrittweisen Entrauschungsprozesses nutzen sie vereinheitlichte Transformer-Modelle, die Text, Code und visuelle Daten in einem gemeinsamen „konzeptionellen Raum“ verarbeiten. Ein Seedream 4.0, das auf einer „Mixture of Experts“-Architektur (MoE) aufbaut, geht noch weiter. Man kann es sich wie ein virtuelles Designteam vorstellen: Ein Experte für Porträts, einer für Typografie, ein weiterer für räumliche Anordnung – alle koordiniert von einer zentralen Intelligenz.
Genau diese Struktur ermöglicht Fähigkeiten, die für Diffusionsmodelle unerreichbar waren:
1. Intelligente Bildbearbeitung und Retusche:
Wer je versucht hat, mit Midjourney ein Detail in einem ansonsten perfekten Bild zu ändern, kennt die Frustration. Meist führt der Weg über externe Programme wie Photoshop. Die neuen Modelle hingegen erlauben eine Bearbeitung mittels natürlicher Sprache. Der Befehl „Mache das Auto rot, aber lasse den Hintergrund unverändert“ wird nicht mehr durch eine ungenaue Maskierung und Neugenerierung umgesetzt. Stattdessen identifiziert das Modell das semantische Objekt „Auto“ und passt dessen Attribute an, ohne die umgebenden Pixel zu beeinträchtigen. Es ist der Unterschied zwischen dem Übermalen eines Fotos und dem Ändern einer Ebene in einer Vektorgrafik
2. Komposition von Layouts und Grafiken:
Hier zeigt sich die wahre tektonische Verschiebung. Die neuen Modelle können angewiesen werden, komplexe Layouts zu komponieren. Ein Prompt könnte lauten: „Entwirf eine Magazinseite im Bauhaus-Stil mit einem Bild einer Architektin oben rechts, einer dreispaltigen Textbox darunter und der Überschrift ‚Die Geometrie des Wohnens‘ in Futura Bold linksbündig.“ Das Modell generiert nicht nur das Bild, sondern arrangiert alle Elemente in einer kohärenten Komposition. Es agiert als Layouter, der Bild und Text in ein sinnvolles Verhältnis setzt.
3. Dynamische Infografiken aus Daten:
Eine weitere bahnbrechende Fähigkeit ist die Visualisierung von Daten. Anstatt eine fertige Infografik als Bild zu beschreiben, kann man dem Modell Rohdaten und einen Stil vorgeben. „Visualisiere die folgenden Quartalszahlen Q1=30, Q2=25, Q3=50, Q4=120 als minimalistisches Balkendiagramm in den Farben Blau und Grau.“ Das Modell interpretiert die Daten und setzt sie in eine grafische Form um. Dies transformiert den Generator von einem reinen Illustrationswerkzeug zu einem mächtigen Instrument für die Datenvisualisierung und das Informationsdesign.
Die Konsequenzen für den kreativen Workflow
Diese erweiterte Funktionalität wird unsere Arbeitsweise als visuelle Gestalter fundamental verändern. Der Prozess wird nicht mehr linear sein – Bild generieren, in Photoshop importieren, Text hinzufügen, Layout in InDesign anfertigen. Stattdessen wird er zu einem integrierten Dialog. Wir werden in der Lage sein, komplexe visuelle Produkte in einem einzigen, iterativen Prozess zu konzipieren und zu verfeinern.
Für Fotografen bedeutet dies zudem die Möglichkeit, konsistente Charaktere über eine ganze Serie hinweg darzustellen, oder auch komplexe Retuschen oder Composings durch präzise Anweisungen zu realisieren. Für Grafikdesigner wird die KI zum Sparringspartner im Layoutprozess, der in Sekundenschnelle Dutzende von Gestaltungsvarianten für eine Broschüre, eine Website oder eine Anzeige vorschlagen kann – komplett mit Platzhaltern für Text und Bild.
Die Rolle des Gestalters verschiebt sich damit weg von der reinen technischen Ausführung hin zur strategischen Direktion. Die entscheidende Fähigkeit wird nicht mehr die Beherrschung eines spezifischen Programms sein, sondern die Fähigkeit, eine klare visuelle Absicht zu formulieren und die KI als intelligenten Assistenten zu dirigieren. Die Kunst des Promptings entwickelt sich von der poetischen Beschreibung eines Bildes zur präzisen Regieanweisung für eine komplexe visuelle Kompositionen.
Wir stehen an der Schwelle zu einer Ära, in der die KI nicht mehr nur Pixel malt, sondern Strukturen versteht. Sie lernt, die Regeln der Bildkomposition der Typografie und des Layouts anzuwenden. Die Magie des schrittweisen Entstehens weicht der Effizienz des ganzheitlichen Verstehens. Das mag weniger poetisch anmuten, eröffnet aber ein Universum an kreativen Möglichkeiten, das weit über die Anfertigung eines einzelnen, schönen Bildes hinausgeht. Die eigentliche Revolution hat gerade erst begonnen.

Bitte in der nächsten DOCMA Heft ein großes Thema über Nano Banana in Photoshop Beta, ist ja jetzt verfügbar und dann auf mehreren Seiten die Einsatzgebiete erklären, mit vielen Best Practise Beispielen.
Ach ja? Habt Ihr das mit dem Bildverständnis mal selbst ausprobiert?
Ich habe den Beispielprompt mit den Quartalszahlen bei Gemini und GPT5 eingegeben. Gemini hat mir als Text beschrieben, was zeichnen würde, war aber nicht in der Lage, die Balken auch sichtbar zu machen.
GPT hat in der Tat vier korrekt skalierte Balken hervorgebracht.
Dann bat ich darum, diese Grafik statt mit Balken mit entsprechend skalierten Geldsäcken zu visualisieren.
Es erschien nach einigem Nachdenken ein Bild mit fünf (!) unterschiedlich großen Geldsack-Symbolen (Umriss mit $-Zeichen drauf), die schlicht von links nach rechts immer größer wurden. Keinerlei Bezug zu den vorher scheinbar korrekt verstandenen Zahlen erkennbar.
Statt des Grafik-Titels „Quartalszahlen“ stand nun auch schlicht „Ascending Value in Money Bags“ drüber.
https://chatgpt.com/s/m_68e412eaa8ec81919555cab44afadcb7
Nach meiner Beschwerde, das habe nichts mit den Quartalszahlen zu tun, erschien dieselbe Grafik nochmal
https://chatgpt.com/s/m_68e413e3b0f08191b3fcbf1bf5f44416
nur dass der Titel jetzt „Ascending Wealth in Navy Blue Bags“ lautet, obwohl die Säcke nach wie vor schwarz sind.
Da werden wir wohl noch ein wenig warten müssen, bis die Revolution tatsächlich beginnt.
Hatte ich ausprobiert, aber das Ergebnis war wie dieses hier nicht sonderlich schick:
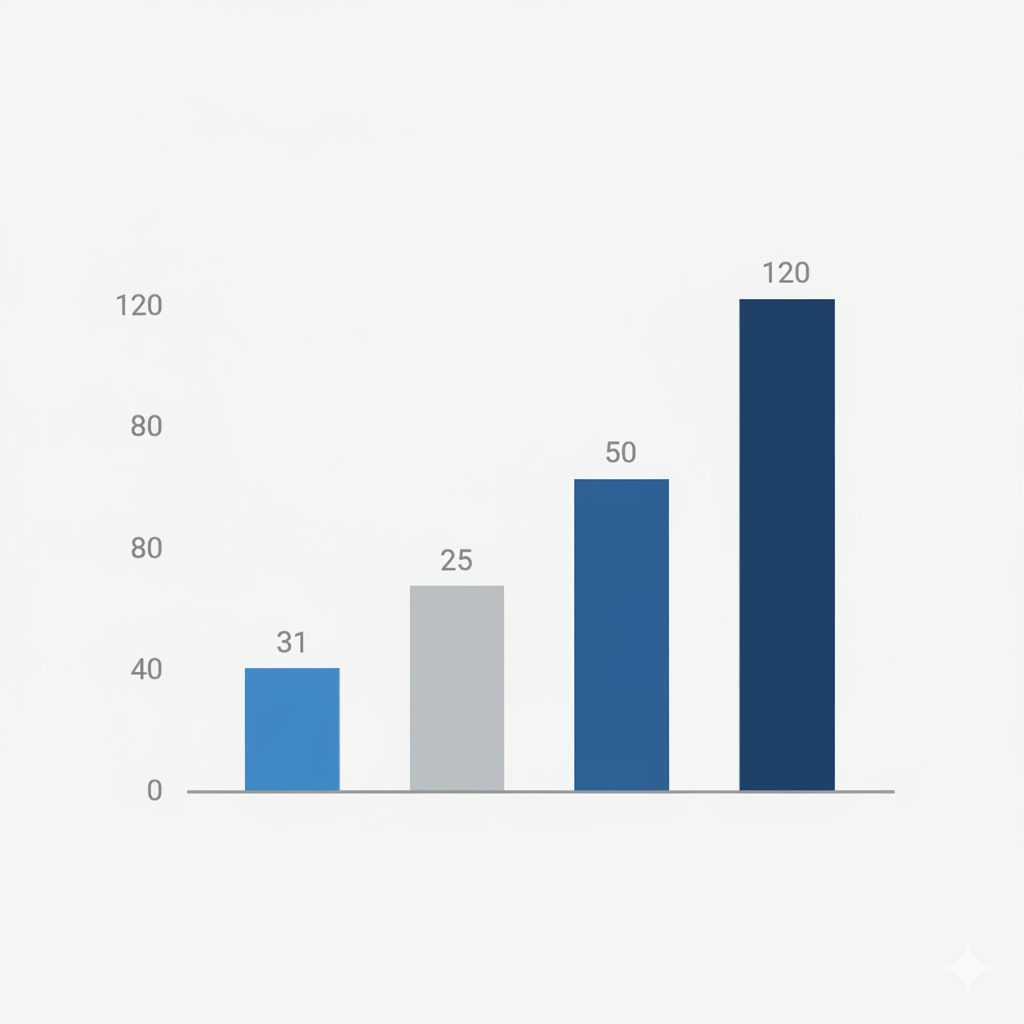
Prompt: Visualisiere die folgenden Quartalszahlen Q1=30, Q2=25, Q3=50, Q4=120 als minimalistisches Balkendiagramm in den Farben Blau und Grau.
und auch noch nicht besonders richtig 🙂