



Google Gemini 2.5 identifiziert Bildinhalte anhand von Anweisungen in natürlicher Sprache
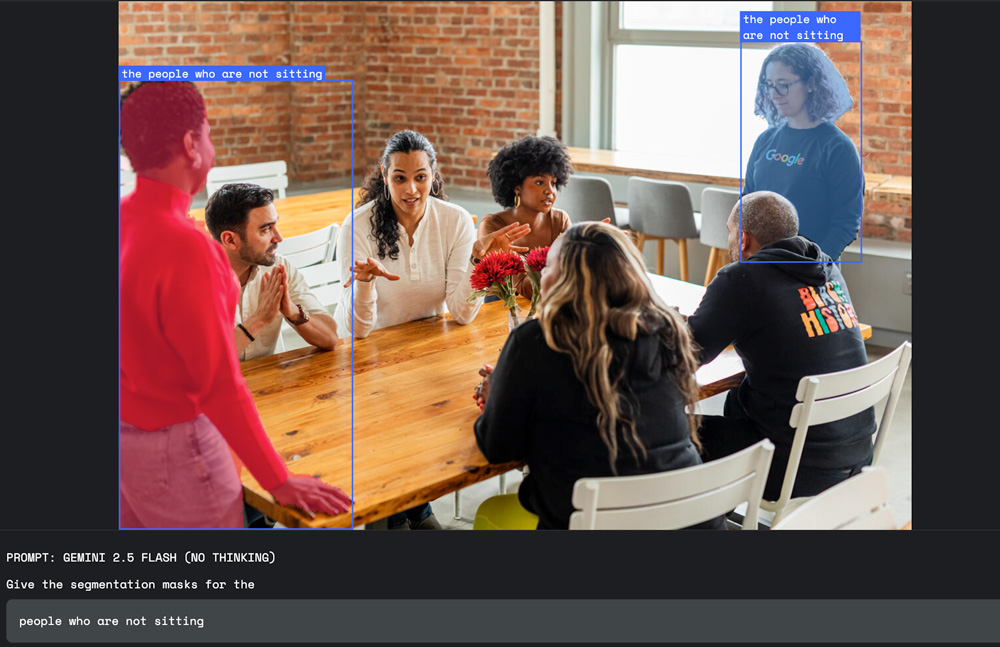
Google hat mit Gemini 2.5 eine bedeutende Erweiterung der KI-Fähigkeiten vorgestellt: die sogenannte „conversational image segmentation“. Diese Funktion erlaubt es, Bildinhalte nicht mehr nur anhand einfacher Objektbezeichnungen zu erkennen, sondern komplexe und natürliche Sprachbefehle zu verstehen und direkt auf einzelne Bildbereiche anzuwenden. Damit macht Google Gemini 2.5 einen wichtigen Schritt in Richtung „Bildverstehen durch Sprachverstehen“ und ermöglicht so eine neue Art des Dialogs zwischen Mensch und Maschine im Bildkontext.
Bislang arbeiteten Bildsegmentierungsmodelle meist mit vordefinierten Kategorien wie „Hund“, „Auto“ oder „Stuhl“ und markierten entsprechende Bereiche mit Rechtecken oder exakten Masken. Die neue Methode geht deutlich weiter: Nutzer können komplexe sprachliche Beschreibungen nutzen, wie beispielsweise „Die Person, die den Regenschirm hält“, „Alle Personen, die nicht sitzen“, „Das beschädigte Haus“ oder „Der Schatten, den das Gebäude wirft“.
Dabei versteht Gemini 2.5 auch abstrakte Begriffe wie „Unordnung“ oder „Schaden“, die keine klar definierte Form haben, sowie logische Bedingungen und Beziehungen zwischen Objekten. Das System erkennt sogar Text innerhalb von Bildern und kann mehrsprachige Eingaben verarbeiten.
Diese Innovation eröffnet vielfältige neue Einsatzgebiete, etwa in der Bildbearbeitung, der Arbeitssicherheit oder dem Versicherungswesen. Bildbearbeiter können Bildteile per Sprache auswählen, zum Beispiel mit der Anweisung „markiere den Schatten des Gebäudes“, ohne umständlich mit der Maus arbeiten zu müssen. Sicherheitsbeauftragte können automatisiert Bilder oder Videos nach Regelverstößen durchsuchen, etwa mit „zeige alle Personen ohne Helm auf der Baustelle“. Und Sachverständige können die Funktion nutzen, um sich beschädigte Gebäude oder Schäden automatisch in Luftbildern markieren zu lassen. In diesem Fall lautet die Anweisung: „Markiere alle Häuser mit Sturmschäden“
Gemini 2.5 nutzt für diese Funktion das Modell „gemini-2.5-flash“. Das Ergebnis der Bildanalyse liefert es in Form von präzisen Segementierungsmasken, Koordinaten und Beschriftungen im JSON-Format. Entwickler können die Funktion über die Gemini-API in eigene Anwendungen integrieren.
Mit „conversational image segmentation“ verbindet Google Vision-KI und natürliche Sprachverarbeitung auf neuem Niveau. Die Möglichkeit, visuelle Inhalte durch natürliche, vielschichtige Sprache zu steuern und verstehen, erleichtert den Umgang mit komplexen Bilddaten deutlich. Das Modell verschiebt die Grenzen von statischer Objekterkennung hin zu dynamischer Kontext- und Zusammenhangerschließung. Damit positioniert sich Google an vorderster Front im Bereich multimodaler KI und bietet insbesondere Kreativen und Fachleuten aus unterschiedlichsten Branchen neue, intuitive Werkzeuge.
Weitere Informationen dazu finden Sie im Google Developers Blog.
