



KI-Prompt Inspiration: Prompts erarbeiten I

Auch wenn die Text-to-image-Systeme absehbar Prompts mit deutschsprachigen Eingaben akzeptieren – noch ist das Englische die Kommunikationssprache, die jeder Promptograf beherrschen sollte. Natürlich tun das die wenigsten Deutsch Sprechenden, wenn sie ganz ehrlich sind. Zumindest, sobald es darum geht, Bilddetails sehr präzise zu benennen. Wir hatten das Thema schon vor einigen Wochen, als ich (zusammen mit der Übersetzung von DeepL) der Meinung war, Kornfelder hießen auf US-Englisch „Cornfields“. Ein Trugschluss. Was macht man dann erst mit Begriffen, die einem helfen würden, aber die man gar nicht kennt?
Prompts erarbeiten mit Describe
Grundsätzlich funktioniert eine Prompt-Bildbeschreibung – das ist nicht anders als bei einem Gespräch – am besten, wenn der Gesprächspartner, hier also die KI, die Worte kennt, mit denen das Bild beschrieben wird. Leider wissen wir meist nicht, was die KI wirklich kennt und nehmen einfach an, ihr sind alle englischen Wörter geläufig, die wir und unserer Übersetzungshelfer auch beherrschen. Erfahrungsgemäß ist das zwar so, aber es gibt darüberhinaus noch viele weitere Wörter. Und da man keine Wortliste abrufen kann, hilft ein kleiner Trick, einige dieser hilfreichen Worte zumindest kontextabhängig kennenzulernen. Grundlage ist bei Midjourney die Describe-Funktion, die ich hier kürzlich schon vorgestellt und erklärt hatte. Bei anderen Bild-KIs habe ich solch eine Funktion bisher nicht entdeckt.
Bilder auswerten
Man beginnt mit einem Bild, das man irgendwo gesehen (und fotografiert oder gespeichert) hat, das einem gefällt und lässt es von Midjourney beschreiben. So hatte ich kürzlich bei Fotofestival La Gacilly-Baden 2023 ein Bild von Rudolf Koppitz entdeckt, das mich sehr an spätere Arbeiten von Leni Riefenstahl erinnerte. Nach der Beschreibung des Bildes von Midjourney erhält man vier Prompts.
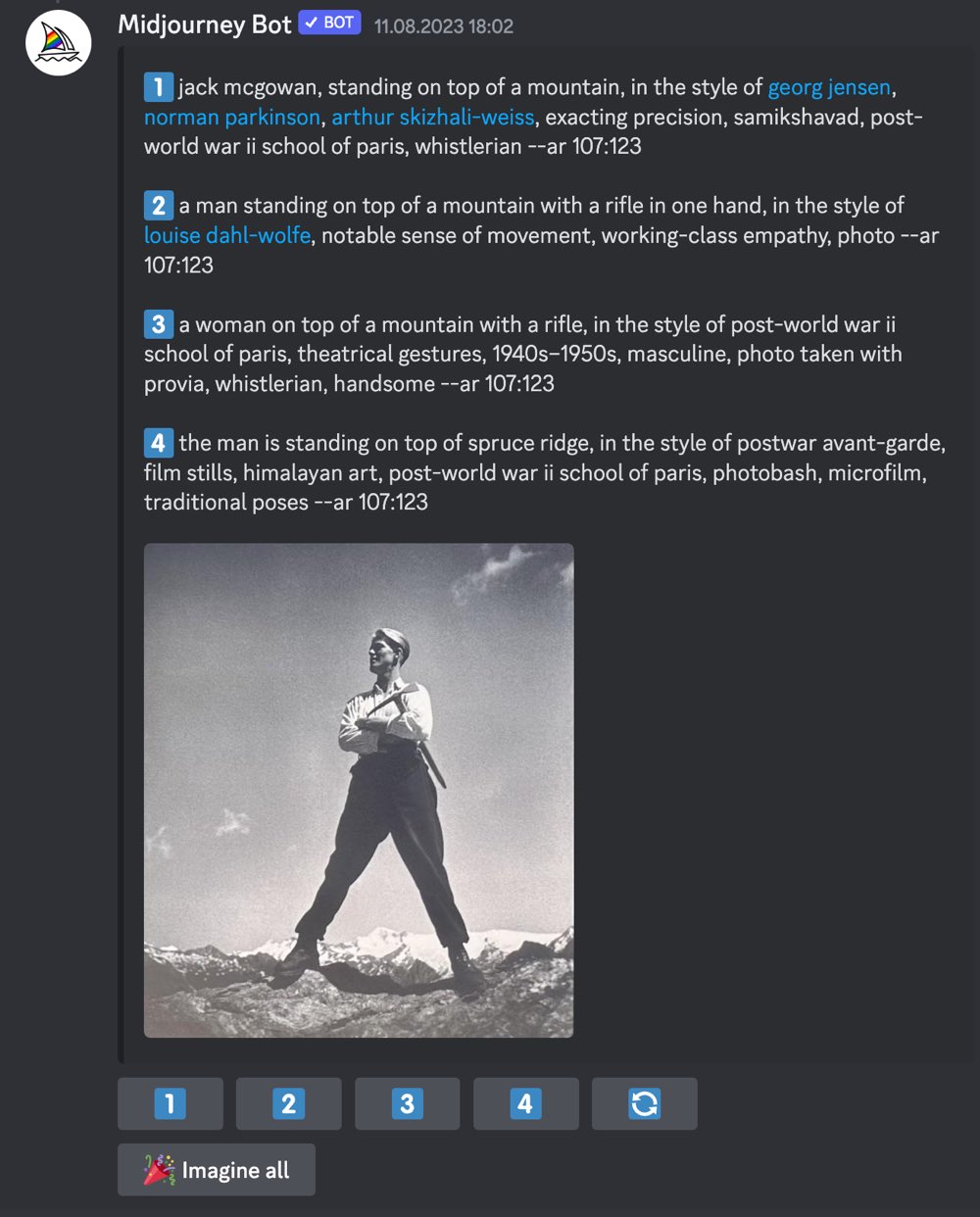
Schauen wir uns den ersten Prompt an und klicken auf die Schaltfläche „1“ zur Berechnung. Midjourney wird wie hier den irischen Schauspieler Jack MacGowran erkannt haben, wie er auf einer Bergspitze steht. Neben drei Künstlern, die stilistisch als Vorlage gedient haben könnten und direkt zur Wikipedia verlinkt sind, lesen wir einen Hinweis zur Ausführung „exacting precision“ und zur „post-world war ii school of paris“. Bis hierhin hätte man das als Kenner der Fotogeschichte vielleicht auch selbst formulieren können. Aber dann finden sich die Worte „samikshavad“ und „whistlerian“, die zumindest DeepL nicht übersetzen kann. Bei Samikshavad handelt es sich um die erste indigene Kunstbewegung im modernen Indien, Whistlerian leitet sich entweder vom Flüsterer (Whistler) ab oder bezieht sich auf den Maler James Abbott McNeill Whistler (1834–1903). Der zweite Begriff passt hier eher.

Sie sehen, man lernt vieles dazu, wenn man Midjourney Bilder als Prompts darstellen lässt. Allerdings ist der Einwand berechtigt, ob es sich hier um Wissen handelt, das weiterhilft. Die zweite Beschreibung ist intellektuell weniger gehaltvoll. Wir lernen hier nur die amerikanische Fotografin Louise Dahl-Wolfe kennen. Außerdem zeigt sich hier wieder einmal Midjourneys Schwierigkeit bei der glaubhaften Darstellung von Handfeuerwaffen.

Das gilt ebenso für die dritte Beschreibung. Der Mann auf dem Ausgangsbild wird von der KI als Frau gelesen. Ansonsten finden sich keine neuen Bezüge.

Von den Bildergebnissen her interessanter ist das schon die vierte Beschreibung. Spätestens jetzt muss man kein Kunsthistoriker mehr sein, um an Caspar David Friedrichs „Wanderer über dem Nebelmeer“ zu denken. Erstaunlicherweise erkennt die KI den Zusammenhang nicht.

Was lernt man?
Grundsätzlich zeigt unser Bespiel, dass die Describe-Funktion eher neue Ideen erzeugt, als das vorgegebene Bild präzise zu beschreiben und damit zu reproduzieren. Ein Umstand, der vermutlich alle erfreut, die Angst haben, die KI würde ihre Arbeiten 1:1 copyrightfrei nachempfindbar machen. Zudem zeigt sich, wie man damit einem selbst bisher unbekannte Künstler oder Kunstrichtungen entdecken kann.
Wie kann man das nutzen?
In erster Linie um neue Vokabeln zur Bildbeschreibung zu erlernen und unbekannte Künstler oder Kunstschulen für bestimmte Bildrichtungen benennen zu können. Ich habe auf diese Weise, eine Vielzahl beschreibender Begriffe dazugelernt und sammle sie inzwischen (samt Übersetzung und Bildbeispiel natürlich) in einer Notizdatenbank.
Aber so richtig weitergebracht auf dem Weg ein ähnliches Bild von der KI nachempfinden zu lassen, hat uns das bishe nicht. Deshalb geht es nächste Woche weiter mit dem Thema.




