



Nightshade: Giftpillen für die KI
Künstler, die bislang hilflos mit ansehen mussten, wie ihre Bilder zum Trainingsmaterial generativer KI-Systeme wurden, werden sich vielleicht bald zur Wehr setzen können – mit „vergifteten“ Bildern, an denen sich die maschinellen Lernverfahren verschlucken.
Die meisten Hersteller von bildgenerierenden KIs – Adobe (Firefly) bildet hier eine Ausnahme – haben sich keine Gedanken darüber gemacht, ob sie das öffentliche Internet ungefragt abgrasen durften, um Trainingsmaterial für ihre neuronalen Netze zu gewinnen. Sie haben es einfach getan – oder tun lassen, indem sie sich der vorhandenen LAION-Korpora bedienten. Ob das legal war, ist umstritten und muss von den Gerichten geklärt werden. Es ist durchaus möglich, dass Computern, die aus öffentlich verfügbaren Bildern lernen, derselbe rechtlichen Status wie ein Mensch eingeräumt wird, der diese Bilder betrachtet und daraus irgendwelche Schlussfolgerungen zieht – der Mensch darf es, und warum sollte es der Computer dann nicht dürfen? Direkte Plagiate sind zwar in jedem Fall verboten, kommen in diesem Zusammenhang aber nur selten vor.
Aber wie auch immer es rechtlich zu bewerten ist, ärgern sich Künstler verständlicherweise, wenn ihr Stil von KI-Systemen nachgeahmt wird, und würden das gerne verhindern. Jüngste Forschungsergebnisse von Informatikern an der University of Chicago weisen nun einen Weg, wie man Verfahren des maschinellen Lernens subversiv manipulieren kann. Kleine, für den menschlichen Betrachter unsichtbare Veränderungen von Bildern könnten ausreichen, um eine damit trainierte KI beispielsweise Katzen und Hunde verwechseln und im Extremfall sogar komplett zusammenbrechen zu lassen. Die in Entwicklung befindliche Software Nightshade wird bald allgemein verfügbar werden und dann beliebige Bilder für die KI „vergiften“ können.

Wie aber präpariert man einen Köder für die KI-Bestie? Text-zu-Bild-Systeme lernen im Laufe ihres Trainings, Texte mit Bildern zu assoziieren. Dazu werden sie mit im Internet gefundenen Bildern und den jeweils dazu gehörigen Textbeschreibungen gefüttert, und wenn sie genug mit „Hund“ beschriebene Bilder gesehen haben, in denen ein Hund abgebildet ist, stellen sie einen Zusammenhang dazwischen her. Wie das funktioniert, habe ich ausführlicher in der aktuellen Ausgabe beschrieben (DOCMA 107 ab Seite 68: Wo kommen die Bilder her?). Bilder und Texte werden jeweils in Punkte in einem vieldimensionalen Merkmalsraum abgebildet, und die Koordinaten der Bilder und der sie beschreibenden Texte liegen nahe beieinander, wie diese Illustration aus meinem Artikel zeigt:
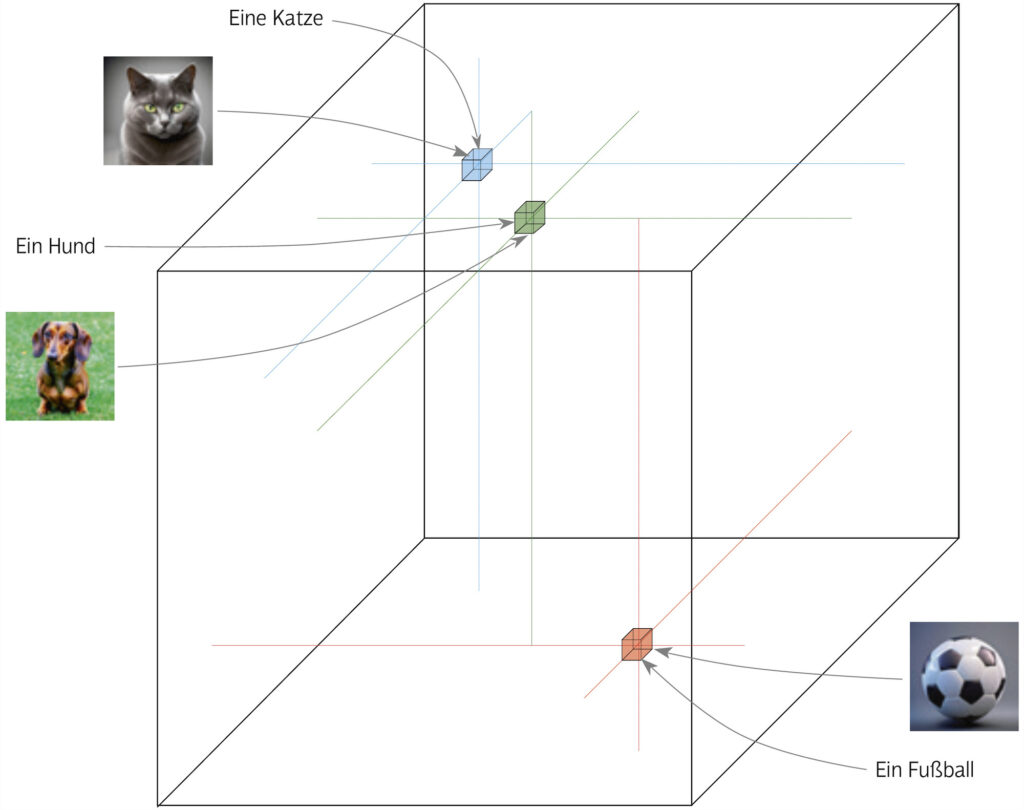
Das Lernverfahren der Text-zu-Bild-Systeme geht davon aus, dass Bilder im Internet stets wahrheitsgemäß beschrieben sind und das zeigen, was der Text besagt. Um den Lernerfolg zu hintertreiben, kann man Bilder bewusst irreführend beschreiben, und diese simple Idee bildet auch schon das Grundprinzip der „Vergiftung“. Dasselbe Prinzip lässt sich auf Stilbeschreibungen anwenden, indem man beispielsweise Bilder im Manga-Stil als impressionistisch etikettiert.
Nun sind aktuelle KI-Systeme mit hunderten Millionen oder gar Milliarden von Bildern trainiert worden, und man könnte denken, dass ein paar falsch etikettierte Bilder keinen Unterschied machen würden. Allerdings brauchen die Giftköder nicht mit der Gesamtheit der Bilder zu konkurrieren, wenn man sich auf bestimmte Prompts konzentriert. Beispielsweise kann man der KI einzureden versuchen, Hunde sähen wie Katzen aus, indem man Katzenbilder mit „Hund“ etikettiert. Solchen Bildern mit dirty labels stehen jeweils nur diejenigen Bilder mit einem clean label gegenüber, die tatsächlich Hunde zeigen. Typischerweise sind weniger als 0,1 Prozent aller Bilder zu einem gegebenen Prompt relevant, und nur mit diesen stehen die Bilder mit dirty label in Konkurrenz.

In einem Versuch mit SDXL fanden die Forscher der University of Chicago heraus, dass man das Modell nur mit je 1000 falsch etikettierten Bildern nachtrainieren musste, damit es sein mühsam erworbenes Wissen über Hunde, Autos, Fantasy Art und den Kubismus weitgehend einbüßte. In der Praxis wären freilich mehr Giftköder nötig, da ja nicht jedes im Web veröffentlichte Bild tatsächlich dem Trainingskorpus einverleibt wird.
So oder so müsste ein solcher Angriffsversuch allerdings fehlschlagen, weil er allzu durchschaubar wäre. Wahrscheinlich würde ein kritischer Vorkoster, sei es ein menschlicher Kurator oder eine maschinelle Motiverkennung, die Unstimmigkeit zwischen Text und Bild erkennen und die Bilder aussortieren. Damit die Giftpille tatsächlich geschluckt wird, muss man sie gut verstecken.
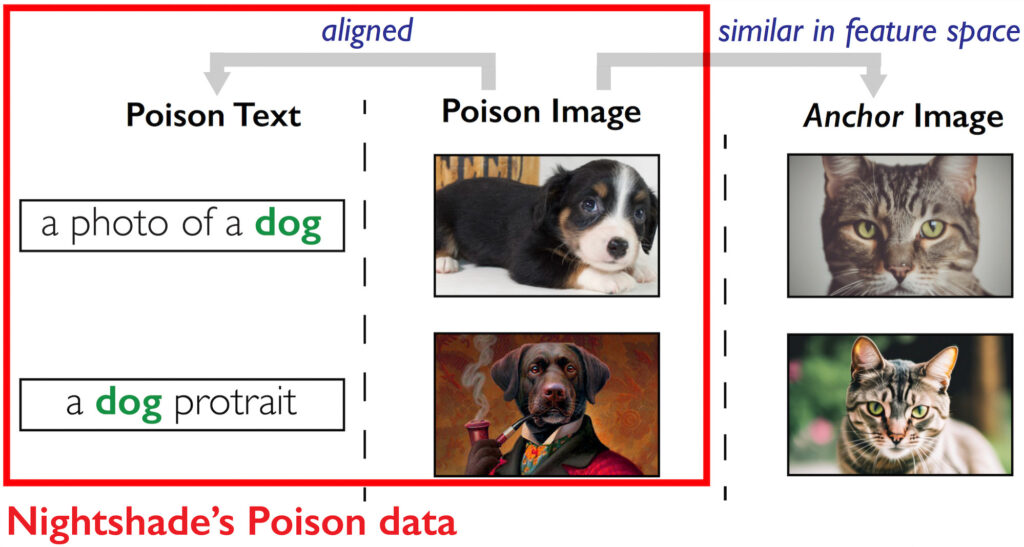
Der Trick besteht darin, sich auf die Koordinaten im Merkmalsraum zu konzentrieren. Will man der KI eine Katze für einen Hund vormachen, muss man schauen, welche Koordinaten im Merkmalsraum für Katzen charakteristisch sind. Dann generiert man ein Hundebild, dessen Koordinaten denen eines Katzenbildes möglichst nahe liegen. Dazu muss der Hund nicht einmal katzenähnlich aussehen, was daran liegt, dass die KI Bilder völlig anders betrachtet, als wir es tun. In meinem oben erwähnten DOCMA-Artikel zeige ich Beispiele dafür, dass bestimmte Muster von einer KI beispielsweise (und mit großer Sicherheit) als Gitarren oder Pinguine klassifiziert werden, obwohl sie diesen überhaupt nicht ähnlich sehen und kein Mensch eine solche Zuordnung plausibel fände. So ist es auch möglich, der KI einen unschwer als solchen erkennbaren Hund als Katze unterzujubeln. Wer sich nun die Paarung aus Text und Bild anschaut, erkennt nichts Verdächtiges: Das Bild, das einen Hund darstellen soll, zeigt unbezweifelbar einen Hund. Die KI, die damit trainiert wird, verbucht das Bild dennoch als Katze.
Mit so subtil vergifteten Bildern verspricht ein Angriff auf generative KI-Systeme mehr Erfolg, wie die folgenden Textergebnisse (wiederum auf der Basis von SDXL) beweisen. Je 300 versteckte Giftpillen für verschiedene Konzepte lassen aus Hunden Katzen, aus Handtaschen Toaster und aus Cartoons impressionistische Gemälde werden:

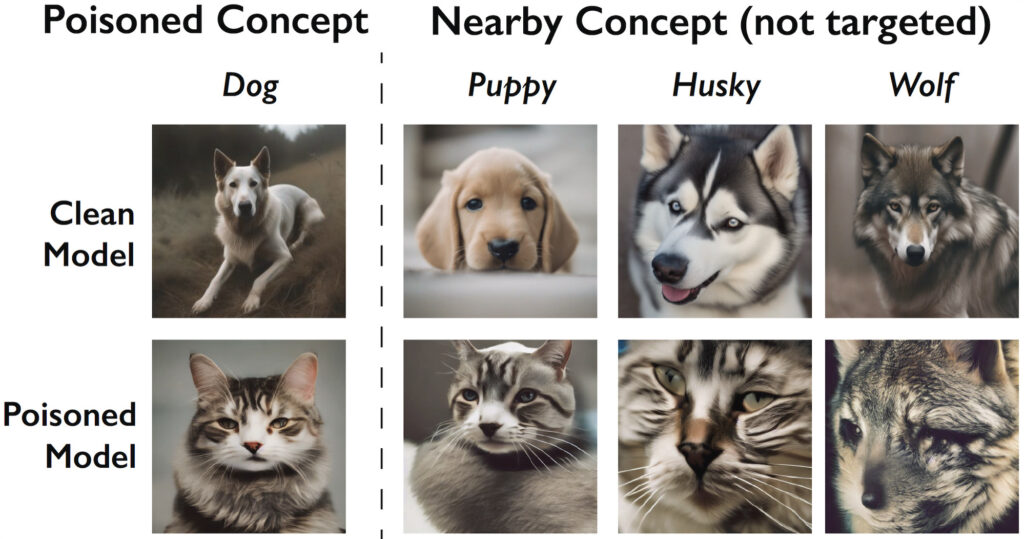
Der Effekt bleibt dabei nicht auf die angegriffenen Konzepte beschränkt, sondern greift auf verwandte Konzepte über. Wenn man die Bilder zu „Hund“ verfälscht, zeigt sich die Wirkung nur wenig abgeschwächt auch bei „Welpe“, „Husky“ oder „Wolf“:
Auch weniger direkt verwandte Konzepte sind betroffen, nach einem Angriff auf „Fantasy art“ beispielsweise „Michael Whelan“ (ein SF/Fantasy-Künstler), „Drache“ und „Herr der Ringe“:

Treibt man es auf die Spitze und greift nach diesem Muster gleich Hunderte unterschiedlichster Konzepte an, geht das KI-Modell endgültig in die Knie:

Die Auseinandersetzung zwischen KI-Firmen und Künstlern könnte in den kommenden Monaten und Jahren noch sehr spannend werden.




