SR3: Bilder aus dem Nichts
KI-gestützte Skalierungsverfahren sind mittlerweile Stand der Technik, aber Googles „Brain Team“ geht noch weiter und entwickelt ein Verfahren, Bilder auf Zuruf zu generieren – erst grob gepixelt, dann immer feiner: SR3.
Die Wissenschaftler im „Brain Team“ von Google Research haben eine neue Superresolution-Methode entwickelt, mit neuronalen Netzen aus niedrig aufgelösten Vorlagen fotorealistische Bilder mit hoher Auflösung zu berechnen. Die Grundidee besteht darin, hoch aufgelöste Beispielbilder zunächst durch Hinzufügen von immer mehr Rauschen in ein reines Rauschbild zu überführen, und dann ein neuronales Netz darauf zu trainieren, diesen Prozess umzukehren, also aus reinem Rauschen realistische Bilder zu generieren.

Die auf diesem Wege erzeugten Details sind natürlich bloß (mehr oder weniger) plausibel erfunden. Oft fällt das nicht weiter auf; dass die rekonstruierten Haarsträhnen des Kindes im folgenden Beispiel ganz anders als im Originalfoto aussehen, bemerkt man im direkten Vergleich; ohne diese Referenz erschiene die frei erfundene Frisur völlig akzeptabel:

In anderen Fällen sehen die Resultate kurios aus, weil die künstliche Intelligenz hier überfordert ist:
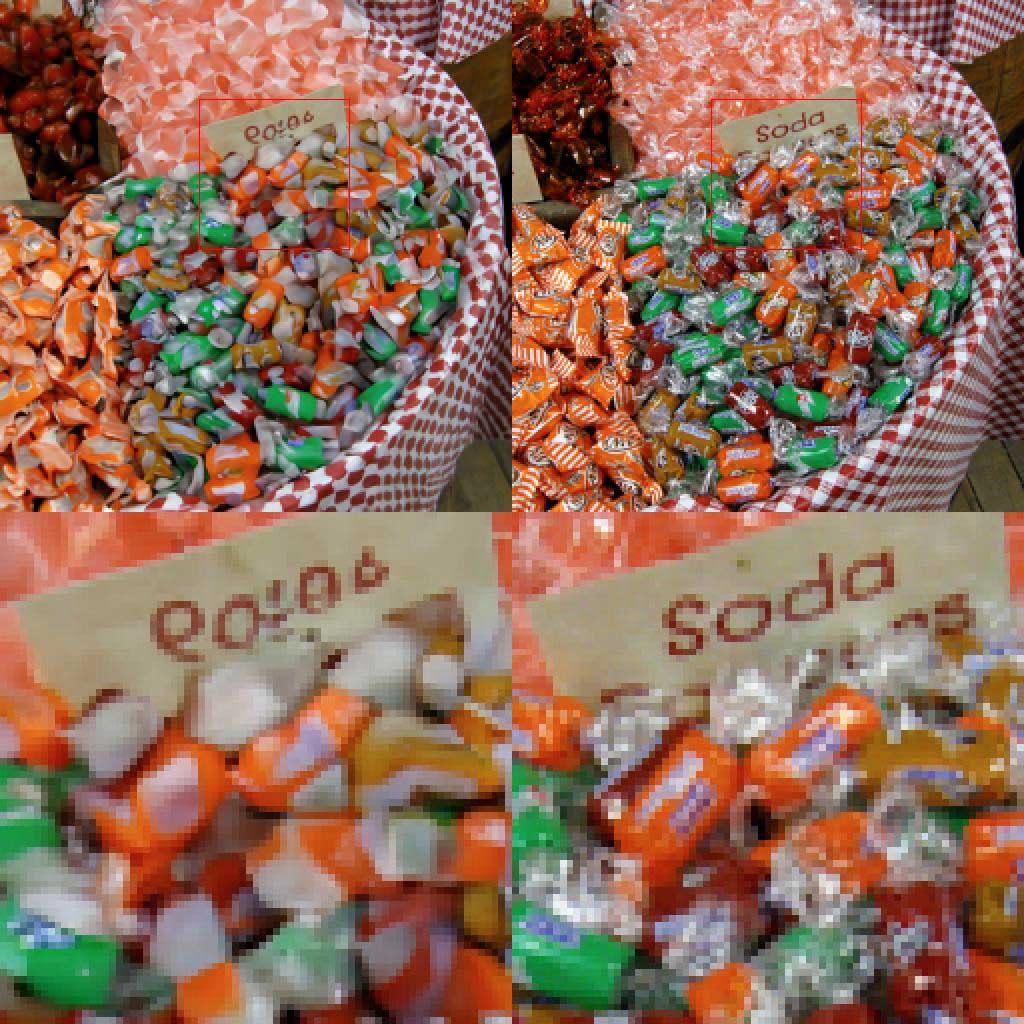
Hier hat SR3 zwar buchstabenähnliche Formen erzeugt, aber es kann nicht erraten, welches Wort (nämlich „Soda“) tatsächlich auf dem Schild steht. Auch die Bonbons scheinen dem neuronalen Netz nicht bekannt zu sein, weshalb ihre Rekonstruktion kaum Details zeigt.
In einer weiteren Arbeit sind die Google-Wissenschaftler nicht von Bildern ausgegangen, sondern von Wörtern. Ein neuronales Netz generiert zunächst ein grob aufgelöstes Bild dessen, was das Wort bezeichnet, und eine nachgeschaltete Superresolution mit SR3 verfeinert dieses Ausgangsbild zu einer fotorealistischen Version. Hier sieht man, was für ein Bild aus dem Input „Straßenbahn“ erzeugt wird:

Möglicherweise sind wir nicht mehr weit von dem Punkt entfernt, an dem wir dem Computer nur noch sagen müssen, was für ein Bild wir brauchen, und eine Software generiert für uns ein copyrightfreies Ergebnis, ohne auf konkrete Foto-Vorlagen für eine Montage zurückgreifen zu müssen. Das wäre dann wohl der Tod der Stockfotografie …