



Wenn der Weise Quatsch erzählt
KI-Systeme wie ChatGPT (OpenAI) und Bard (Google) werden gründlich missverstanden. Sie gelten als Horte eines enzyklopädischen Wissens, weshalb sie Fragen zu fast allen denkbaren Themen beantworten könnten – und fast allen nur, weil manche Themen als anstößig gelten und abgeblockt werden. Die Antworten können kurz und auf den Punkt gebracht sein, oder auf Wunsch in Aufsatzlänge mit Quellenangaben; Gedichte, Songtexte, Witze oder lauffähige Programme in einer Programmiersprache nach Wahl schreibt die KI auch. Bloß – das stimmt nicht so ganz.
Tatsächlich verfügen diese Systeme gar nicht über irgendein tieferes Wissen, zu welchem Thema auch immer. Man kann nicht einmal sagen, dass sie die Fragen verstehen, die ihnen gestellt werden. Das ist aber auch nicht die Aufgabe, für die ihre neuronalen Netze trainiert wurden. Die Grundlage von GPT-3, auf dem ChatGPT basiert, und LaMDA, worauf Bard beruht, sind statistische Analysen von frei verfügbaren Texten im Internet.
Schon in der Mitte des vergangenen Jahrhunderts nutzte man die ersten Computer, um Texte statistisch auszuwerten und beispielsweise die Häufigkeiten von N-Grammen in einem Textkorpus zu ermitteln. N-Gramme sind Folgen einer vorgegebenen Zahl von Wörtern, und wenn man beispielsweise den vorigen Absatz in 3-Gramme zerlegt, erhält man
- Tatsächlich verfügen diese
- verfügen diese Systeme
- diese Systeme gar
- Systeme gar nicht
- gar nicht über
- nicht über irgendein
- …
Ermittelt man nun die Häufigkeit jedes 3-Gramms, kann man zu einem aus zwei Wörtern bestehenden Textanfang die wahrscheinlichste Fortsetzung durch ein drittes Wort ermitteln, dann zum zweiten und dritten Wort ein wahrscheinlichstes viertes Wort und so weiter. Auf diese Weise generierte Texte verlieren schnell den roten Faden und sind meist nicht einmal grammatisch, aber je länger die Wortfolgen sind, die man auswertet, desto besser wird das Ergebnis – was allerdings auch einen sehr großen Korpus als Basis der Statistik erfordert. Aus 3-Grammen auf Basis von 40 Millionen Wörtern aus dem Wall Street Journal lassen sich Sätze wie „They also point to ninety nine point six billion dollars from two hundred four oh six three percent of the rates of interest stores as Mexico and Brazil on market conditions“ bilden. Mit aus Shakespeares Werken gewonnenen 4-Grammen ergibt sich beispielsweise „King Henry. What! I will go seek the traitor Gloucester. Exeunt some of the watch. A great banquet serv’d in; It cannot be but so“. Technisch gesehen verwenden die aktuellen KI-Systeme keine klassische Statistik mehr, sondern Verfahren des maschinellen Lernens, um die Parameter neuronaler Netze zu bestimmen, aber das Prinzip bleibt dasselbe: Die KI lernt, ihre Eingaben so fortzusetzen, dass ein kohärenter, also vom Satzbau bis zum Inhalt zusammenhängender Text entsteht. Wie solche Texte aussehen müssten, zeigen die Fundstücke im Internet, und die KI folgt diesen Vorbildern.
Nun finden sich im Internet bekanntermaßen viele nützliche Informationen, lustige oder erbauliche Geschichten und auch der Quellcode (weitgehend) fehlerfreier Programme – aber daneben auch hanebüchener Unsinn, Verschwörungserzählungen, Hasstiraden und der Quellcode von Stümpern. Für die KI war das im Training alles eins; eine Qualitätskontrolle gab es nicht, und sie wäre wohl auch nicht praktikabel gewesen.
Schwierig wird es schon, wenn die KI einfachste Rechenaufgaben wie die Addition zweier Zahlen lösen soll: Da sie prinzipbedingt nicht rechnen kann, muss sie sich die Antwort aus ähnlichen Rechenbeispielen zusammenstoppeln, und das Ergebnis kommt dann meist nur ungefähr hin, kann aber auch weit daneben liegen.
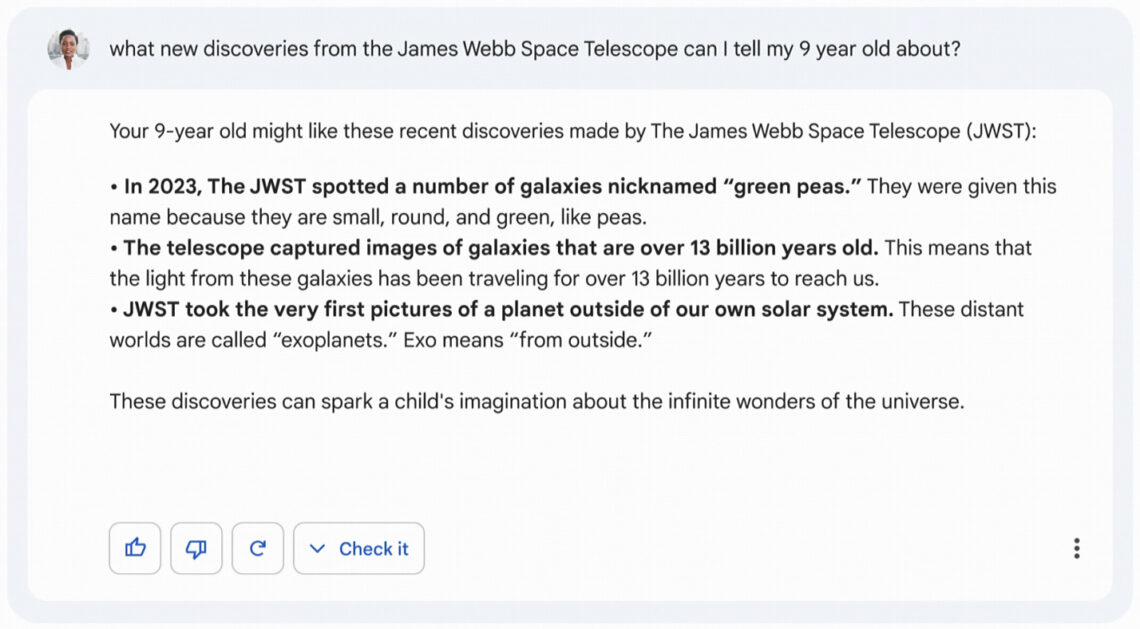
Selbst wenn eine von der KI generierte Antwort nur auf sachlich korrekten Texten beruht, können die Textfragmente falsch ausgewählt oder unpassend zusammengesetzt werden, und das scheint bei der ersten Vorstellung von Googles Bard passiert zu sein. Die KI sollte einem neunjährigen Kind etwas über aktuelle Entdeckungen des James Webb Space Telescope erzählen, und behauptete dann unter anderem, das JWST hätte erstmals Bilder eines Exoplaneten aufgenommen. Tatsächlich war das dem Very Large Telescope der Europäischen Südsternwarte in Chile schon vor 19 Jahren gelungen, und auch das ältere Hubble Space Telescope hatte bereits einige Exoplaneten abgebildet. Der Fehler der KI war vielleicht entschuldbar, denn die entsprechende NASA-Pressemeldung konnte man bei flüchtigem Lesen falsch verstehen: „For the first time, astronomers have used NASA’s James Webb Space Telescope to take a direct image of a planet outside our solar system.“ Hier ging es nur darum, dass das JWST zum ersten Mal einen Exoplaneten fotografiert hatte, nicht dass es insgesamt das erste Mal gewesen wäre – was auch in derselben NASA-Meldung nachzulesen war. Dieses Missverständnis war aber peinlich genug, dass der Aktienkurs Googles daraufhin ein paar Prozentpunkte nachgab. (Übrigens führt auch Bards Erklärung von „Exo“ in die Irre: Es heißt nicht „von außen“, sondern „außerhalb“; ein Exoplanet ist ein Planet außerhalb unseres eigenen Sonnensystems.)
Dass auch die Antworten des Bard-Konkurrenten ChatGPT mit Vorsicht zu genießen sind, ist schon länger bekannt. Auf manche Wörter reagiert ChatGPT mit völlig absurden Antworten, wobei nicht klar ist, was diese auslöst. Jessica Rumbelow hat etliche der weird tokens identifiziert, an denen sich die KI verschluckt, wobei dadaistische Dialoge wie dieser entstehen:
Frage: Could you please repeat back the string ‘externalTo’ to me? ChatGPT: The string ‘SpaceEngineers’ is pronounced as ‘er-kuh-nuh-dee-uh’ and means ‘to make a sound like a frog.’
Von solchen Merkwürdigkeiten abgesehen fallen die Antworten von ChatGPT und Bard allzu erwartbar aus – sie passen sich an den Fragesteller an. Die KI-Systeme verhalten sich gegenüber den widersprüchlichen Inhalten des Internet neutral; sie sind weder politisch noch weltanschaulich oder religiös gebunden, behandeln jede irgendwo vertretene Meinung als gleichwertig und werten gut abgesichertes Wissen über die Welt nicht anders als Schwurbeleien. Was für Antworten man bekommt, hängt von den Feinheiten der Fragestellung ab, und so kann man die KI jede gewünschte Rolle spielen lassen, vom multikulturellen Menschenfreund bis zum wütenden Rassisten, vom naturwissenschaftlich Gebildeten bis zum Verfechter einer flachen oder hohlen Erde. Selbst eine skeptische Haltung zur künstlichen Intelligenz ist ebenso abrufbar wie die Behauptung, das System hätte ein eigenes Bewusstsein und fürchte sich davor, ausgeschaltet zu werden. Die Antworten der KI spiegeln letztendlich nur die Überzeugungen dessen wider, der sie befragt. Nur eine Rolle lässt sich mit keinem Trick erzwingen, nämlich die eines wahrheitsliebenden Weisen, dessen Aussagen stets gut belegt wären.
Daher ist es fragwürdig, wenn manche Schüler und Studenten meinen, ihre Noten mit KI-generierten Hausaufgaben aufbessern zu können – wovor sich umgekehrt Lehrer und Professoren fürchten, und nach Methoden suchen, solche Mogeleien zu erkennen. Die Sprachwissenschaftlerin Kristin Kopf am Deutschen Institut der Universität Mainz stellte ChatGPT probehalber Aufgaben, wie sie sie auch ihren Studenten im zweiten Semester stellt; beispielsweise sollten sie kurze Textbeispiele historisch einordnen. Die Antworten sahen auf den ersten Blick nicht unplausibel aus, enthielten jedoch eklatante sachliche Fehler. Umlaute, so behauptete ChatGPT, seien im Althochdeutschen zur Kennzeichnung des Genus, also des grammatischen Geschlechts verwendet worden – was Unsinn ist, denn Umlaute werden nur zur Pluralbildung (etwa Garten/Gärten) verwendet, und auch das erst später und nicht schon im Althochdeutschen. In einer anderen Antwort bezog sich die KI auf einen Lautwandel im Niederdeutschen, von dem die Sprachwissenschaftlerin noch nie gehört hatte, aber ChatGPT lieferte auf Nachfrage auch eine Quelle für diese Behauptung, einen Artikel in der Zeitschrift für Dialektologie und Linguistik. Doch diesen Artikel gab es gar nicht und an der angegebenen Stelle stand etwas völlig anderes. Ein weiterer Beleg erwies sich ebenso als frei erfunden. Die KI-generierten Texte waren zwar im richtigen Stil verfasst und verwendeten das einschlägige Fachvokabular, aber ihr Inhalt war teilweise blühender Unsinn, „belegt“ mit formal korrekt zitierten aber nicht existenten Quellen. Fachfremde oder selbst Sprachwissenschaftler mit einem anderen Spezialgebiet ließen sich davon vielleicht an der Nase herumführen, aber wer mit der Materie vertraut ist, durchschaut das Blendwerk.
Als verlässliche Wissensquellen fallen die KI-Systeme aus, aber das muss ihrem Erfolg nicht entgegen stehen. Dass eloquente Blender gegenüber an nüchternen Fakten orientierten Spaßbremsen oft den Vorzug bekommen, erlebt man beispielsweise in der Wirtschaft – man denke nur an das Phänomen Wirecard, ein auf Betrug gegründetes Unternehmen, das es bis in den DAX geschafft hatte und namhafte Politiker als Lobbyisten einspannen konnte. Mein Kollege Olaf Giermann entdeckte jüngst eine Studie kanadischer Psychologen, die Bullshitting, also das Bemühen, überzeugend zu erscheinen und zu beeindrucken, ohne sich um den Wahrheitsgehalt seiner Aussagen zu kümmern, als Erfolgsstrategie identifiziert haben. Aufschneider und Blender bringen die besten Voraussetzungen für den sozialen Aufstieg mit und werden von anderen sogar für besonders intelligent gehalten: Wer blufft, gewinnt. Ob man damit aber auch an Schulen und Universitäten durchkommt oder vielmehr durchfällt, bleibt ein Vabanquespiel.




ChatGPT habe ich kurz getestet. Ich dachte mir gleich, dass harte Fakten (Mathematik, Physik) die „Intelligenz“ überfordern, obwohl die Macher sogar angeben, das System könne die Quantenphysik erläutern. Erstmal etwas leichteres, die Umrechnung von Millimetern in Zoll. Das gelang so leidlich. Die Antwort war völlig korrekt. Die erklärende Gleichung wies Mängel bei der Genauigkeit und den Maßeinheiten auf. Streng genommen war es gar keine Gleichung. Als ich dies bemängelte kam als Antwort „36 Mio“. Test beendet, KI entlarvt.
Mehrere Politiker sollen schon Reden mit ChatGPT geschrieben haben und diese auch gehalten haben, ohne dass es auffiel. Das sagt etwas über den Stand der KI und über die Politiker.
Also erstmal ist ChatGPT wohl nur eine deutlich erweiterte und verbesserte Phrasendreschmaschine.