


Generative KI: Wo kommen die Bilder her?

Generative KI-Systeme wie Midjourney, Stable Diffusion und Firefly sind ein offenbar unerschöpflicher Quell immer neuer Bilder. Michael J. Hußmann erklärt, wie sie entstehen.
Wenn Text-zu-Bild-Systeme noch die abseitigsten Prompts halbwegs passend visualisieren, fühlt man sich an einen Zaubertrick erinnert: Ein Illusionist zieht ein Kaninchen nach dem anderen aus seinem Zylinder, in dem unmöglich genug Platz für all die Tiere gewesen sein kann. Wo nehmen Midjourney & Co. ihre Bilder her? Diese KI-Systeme haben nicht einmal einen Speicher, in dem sie enthalten gewesen sein könnten.
Die generative Magie basiert auf künstlichen neuronalen Netzen, also einer stark vereinfachten Simulation eines Nervensystems. Die simulierten Nervenzellen (Neuronen) haben Eingänge, über die sie mit den Ausgängen anderer Neuronen verbunden sind. Wenn die Summe der Werte an den Eingängen einen Schwellwert überschreitet, „feuert“ das Neuron und gibt einen Wert an seinem Ausgang aus, der wiederum mit den Eingängen weiterer Neuronen verknüpft ist. Die neuronalen Netze der KI bestehen heutzutage aus Millionen solcher simulierten Neuronen und einer noch viel größeren Zahl von Verbindungen zwischen ihnen. Generative KI-Systeme enthalten typischerweise mehrere Schichten von Neuronen: Eine Input-Schicht, in die ein Prompt-Text eingespeist wird, weitere Schichten für die eigentliche Verarbeitung und schließlich eine Output-Schicht, die das Bildergebnis erzeugt.
Was das neuronale Netz tut, wird durch seine Verschaltung bestimmt, also vor allem durch die Stärke der Verbindungen zwischen den Neuronen. Diese Variablen bilden gewissermaßen die Software der KI und werden als sogenanntes Modell gespeichert. Schaut man sich die Größe der Modelldateien an, dann sind sie viel kleiner als der Korpus aus Milliarden von Bildern, mit dem die KI für ihre Aufgabe trainiert worden war, aber auch kleiner als der Strom von Bildern, der daraus generiert werden kann. Wie bei den aus dem Hut gezogenen Kaninchen muss ein Trick hinter der generativen KI stecken, aber wie funktioniert er?
Der entscheidende Punkt ist, wie man Bilder im Computer repräsentiert. Wir kennen vor allem Bitmaps, also Bilder, die aus Zeilen und Reihen von Pixeln bestehen. Für die Zwecke der generativen KI möchte man die Bilder dagegen so repräsentieren, dass ähnliche Bilder auch als ähnliche Folgen von Bits und Bytes gespeichert werden. Mit RGB-Bitmaps, wie wir sie in Photoshop bearbeiten, funktionierte das nicht: Wenn wir mehrere Fotos einer Katze vergleichen, die sie von vorne, von hinten, von der Seite und mit unterschiedlichen Körperhaltungen zeigen, dann sind sich die RGB-Bilder nicht besonders ähnlich. Die Pixel für Pixel berechnete Differenz kann auch mal größer als die zwischen dem Bild der Katze und dem eines Hundes ähnlicher Fellfarbe sein. Statt durch die Farbe der einzelnen Pixel kann man die Bilder aber durch ihre Merkmale beschreiben. Für eine ausreichend treffgenaue Beschreibung sind Tausende, wenn nicht Millionen von Merkmalen nötig, aber für ein neuronales Netz ist es keine Herausforderung, Bilder darin umzurechnen. Für diese Aufgabe muss es lediglich mit Milliarden von Bildern trainiert werden. Das Netz liefert dann zu jedem Bild die Werte seiner Merkmale, also Koordinaten in einem vieldimensionalen Merkmalsraum. Die Merkmale können beispielsweise Alter, Geschlecht, Farbe und Aggregatzustand (sofern jeweils anwendbar) sein, aber auch Eigenschaften, die das neuronale Netz im Training selbst entdeckt hat.
Der Name für die so gefundenen Koordinaten lautet Embedding, aber den vergessen Sie am besten gleich wieder. In der KI werden alltäglich gebrauchte Wörter wie Embedding (Einbettung) oder Attention (Aufmerksamkeit) als Fachbegriffe in einer ganz anderen als der vertrauten Bedeutung verwendet. Außerhalb der Wissenschaft verwirrt das nur, weshalb ich diese Wörter hier vermeide.
Es macht übrigens nichts, wenn Sie sich einen vieldimensionalen Raum nicht anschaulich vorstellen können – das kann vermutlich niemand. Wichtig zu wissen ist nur, dass ähnliche Bilder ähnliche Merkmale haben und daher im Merkmalsraum benachbart sind. Sie liegen sich darin um so näher, je mehr sie sich ähneln. Alle Bilder derselben Katze finden sich in einem eng begrenzten Gebiet, umgeben von einer Zone mit Bildern anderer Katzen, während die Hundebilder in einer anderen, weiter entfernten Zone liegen. Bilder von Buschwindröschen, Einfamilienhäusern und Fußbällen liegen wiederum ganz woanders. Da das neuronale Netz im Training lernen musste, zu verallgemeinern, funktioniert das meist auch mit Bildern, die es noch nie zuvor gesehen hat.
Die Bilder sind zwar nach ihrer Umwandlung in Koordinaten im Merkmalsraum verschwunden, aber diese Form der Repräsentation erlaubt bereits einige nützliche Anwendungen. Inhaltsbasierte Vergleiche zweier Bilder sind trivial: Man ermittelt ihre Koordinaten und berechnet deren Abstand, der ein Maßstab für ihre Ähnlichkeit ist. Anhand seiner Koordinaten kann man auch leicht herausfinden, ob ein Bild eine Katze, einen Hund, ein Buschwindröschen oder einen Fußball enthält, da man die Bereiche des Merkmalsraums kennt, in dem Bilder solcher Motive liegen.
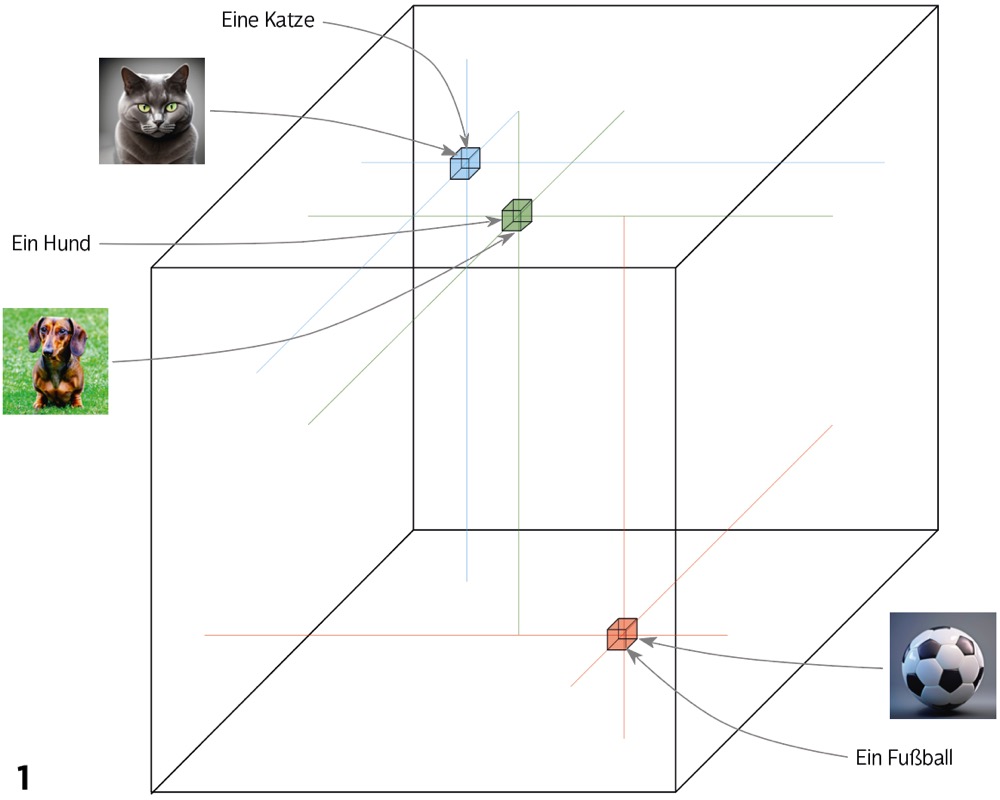
Noch interessanter wird diese Art der Repräsentation, wenn man zum Training Bilder mit einem deren Inhalt beschreibenden Text verwendet. Dann kann man neben einem neuronalen Netz für die Bilder ein zweites für die Texte trainieren – und zwar so, dass den Texten dieselben oder zumindest sehr ähnliche Koordinaten im Merkmalsraum wie den beschriebenen Bildern zugeordnet werden (Bild 1). Auch das neuronale Netz für die Texte muss dabei lernen, zu verallgemeinern, wird also auch für solche Texte passende Koordinaten finden, die im Trainingskorpus nicht vorkamen.
Man könnte denken, dass sich damit bereits ein Text-zu-Bild-System verwirklichen ließe, da man die zu einem Prompt zugehörigen Koordinaten berechnen kann, die gleichzeitig die Koordinaten eines so beschriebenen Bildes sind. Umgekehrt ließe sich zu einem Bild eine passende Bildbeschreibung finden. Aber ganz so einfach ist es nicht.
Aus einem Text können wir zwar Koordinaten berechnen, die gleichzeitig die Koordinaten der gewünschten Bilder sind. Diese Bilder müssen aber erst noch aus den Koordinaten berechnet werden, während wir bislang nur ein Verfahren für den umgekehrten Weg haben, also zur Berechnung von Koordinaten aus Bildern. Dazu ist ein drittes neuronales Netz nötig, das zur Bildgenerierung ein Diffusionsverfahren anwendet. Nach dieser Methode der Diffusion ist Stable Diffusion benannt, aber sie liegt auch anderen Systemen wie Midjourney und Firefly zugrunde.
Das Diffusionsverfahren soll aus dem Nichts beliebige Bilder erzeugen, und „Nichts“ heißt in diesem Fall: Rauschen. Um ein neuronales Netz darauf zu trainieren, im Rauschen Bilddetails zu erkennen, geht man zunächst den umgekehrten Weg und fügt Bildern schrittweise immer mehr Rauschen hinzu, bis sie nur noch aus Pixeln mit zufälligen Farb- und Helligkeitswerten bestehen. Das neuronale Netz muss dann lernen, die verrauschten Bilder wieder zu entrauschen, also jeweils das Bild aus dem Schritt davor zu rekonstruieren, das noch weniger Rauschen enthielt (Bild 2).

Diffusion-Modell darauf trainieren, verrauschte Bilder in der umgekehrten Richtung Schritt für Schritt zu entrauschen (b). Illustration: Michael J. Hußmann
Mit dem austrainierten Diffusions-Netz kann man dann aus reinem Rauschen ein Bild berechnen, in dem sich bereits erste Motivdetails erahnen lassen. Diesem wird erneut ein wenig Rauschen hinzugefügt, woraufhin der Vorgang wiederholt wird. Schritt für Schritt treten die Motive klarer hervor, und am Ende erhält man ein rauschfreies, detailreiches Ergebnis. Auf diesem Wege entstehen allerdings völlig beliebige Bilder, während ein Text-zu-Bild-System ja ganz bestimmte Bilder generieren soll – nämlich solche, die zu einem vorgegebenen Prompt passen. Dieser muss also die Bildgenerierung in die gewünschte Richtung steuern.
Beim Trainieren des Diffusions-Netzes gehört deshalb neben dem verrauschten Bild auch dessen Beschreibung zum Input – oder vielmehr deren Koordinaten im Merkmalsraum. Das Netz soll lernen, das verrauschte Bild nicht unbedingt im Sinne der vorgegebenen weniger verrauschten Version zu verbessern, sondern nur, wenn ein entsprechender Text als Prompt vorliegt. In der Praxis zeigt sich, dass dies als Steuerung der Bildgenerierung noch nicht ausreicht, aber hier hilft ein Kniff, den Einfluss eines Prompts zu vergrößern. Dazu lässt man das neuronale Netz zwei entrauschte Bilder berechnen, eines mit Berücksichtigung des Prompt und eines ohne. Die Differenz beider Bilder zeigt dann an, in welche Richtung der Prompt die Generierung steuert, und wenn man diese Differenz mit einem Faktor multipliziert und dem ohne Prompt generierten Bild hinzufügt, wird die steuernde Wirkung des Prompt verstärkt. Dieser Faktor ist der Guidance-Parameter, den man in manchen Text-zu-Bild-Systemen frei wählen kann.
Das Verfahren, mit dem der Prompt die Bildgenerierung anleitet, ist ein wichtiger Faktor, der die Qualität der Ergebnisse bestimmt. Daher experimentieren die Hersteller generativer KI-Systeme mit verschiedenen Guidance-Strategien, um die typischen Fehler solcher Systeme (siehe DOCMA 106 ab Seite 80) künftig zu vermeiden.
Prinzipiell wäre es auf diesem Wege auch möglich, die Erzeugung überzähliger Gliedmaßen zu vermeiden, aber abgesehen davon, dass sich die neuronalen Netze mit dem Zählen von Elementen schwer tun, müssten dazu stark verrauschte Bilder analysiert werden, wenn die Generierung rechtzeitig in die richtige Bahn gelenkt werden soll. Die entscheidenden Details zeichnen sich in dieser frühen Phase allerdings noch kaum im Rauschen ab.
Ein aktuell verfolgter Ansatz beruht darauf, Bilder nach ihren ästhetischen Qualitäten von Menschen bewerten zu lassen und mit diesen Daten ein neuronales Netz zu trainieren, das die erlernten ästhetischen Maßstäbe an die Zwischenstufen zum fertigen Bild anlegt und so die Generierung steuert. Leider ist es nicht praktikabel, Menschen unmittelbar in den Trainingsprozess einzubinden, da dieser Milliarden von Durchläufen umfasst und mit menschlichen Eingriffen viele Jahre in Anspruch nähme.
Das vom Diffusion-Netz erzeugte Bild hat schließlich eine Auflösung von beispielsweise 64 × 64 oder 128 × 128 Pixeln, mit der man in der Praxis noch wenig anfangen könnte. Eine von vornherein höhere Auflösung würde derzeit noch zu viel Rechenleistung beanspruchen. Daher muss ein weiteres neuronales Netz das Bild erst noch auf eine sinnvoll verwendbare Größe hochskalieren – in der grundsätzlich gleichen Weise, wie man das mit einer Software wie Topaz Gigapixel AI erreichen würde. Der Prompt spielt dabei keine Rolle mehr, da nur noch feine Details hinzugefügt werden.
EXKURS: Lernen, aber richtig
Im Training soll ein neuronales Netz lernen, zu einem bestimmten Input einen vorgegebenen Output zu erzeugen. Dabei könnte sich das Netz einfach aus der Affäre ziehen, indem es alle im Training verwendeten Kombinationen von Input und Output auswendig lernt. Damit wäre allerdings nichts gewonnen, denn das Netz würde nur zu den Eingaben aus dem Trainingskorpus die richtigen Resultate liefern, bei allen anderen aber versagen. Damit es nach Abschluss des Trainings auch mit unbekannten Eingaben zurecht kommt, muss man die Größe des Netzes beschränken – Auswendiglernen erfordert viel Speicherplatz, während ein kleineres Netz nur dann zu einem Trainingserfolg kommt, wenn es aus den Beispielen zu generalisieren gelernt hat. Andererseits darf es aber auch nicht zu klein bemessen sein, weil es der Aufgabe dann nicht gewachsen wäre.
Tiefe neuronale Netze vorm Transformer-Typ, wie sie zur Berechnung der Koordinaten von Bildern oder Texten im Merkmalsraum eingesetzt werden, nutzen dasselbe Prinzip: Von ihrer Input-Schicht aus nimmt die Zahl der Neuronen in den weiteren Schichten zunächst ab, um bis zur Output-Schicht wieder zuzunehmen. Die künstlich gebildete Engstelle zwingt das Netz im Training dazu, eine kompakte Repräsentation der Eingaben zu finden – es lernt also, die Eingabedaten zu komprimieren – zum Beispiel als Koordinaten im Merkmalsraum.
Das ist doch gar kein Pinguin!
Das Training der Umwandlung von Bildern in Koordinaten führt erfahrungsgemäß nicht zu hundertprozentig perfekten Ergebnissen. In manchen Mustern (b), in denen wir kein bestimmtes Objekt erkennen können, sieht das neuronale Netz Motive wie beispielsweise einen Pinguin oder eine Gitarre, und das mit vermeintlich ebenso großer Sicherheit wie bei einer korrekten Klassifizierung (a).
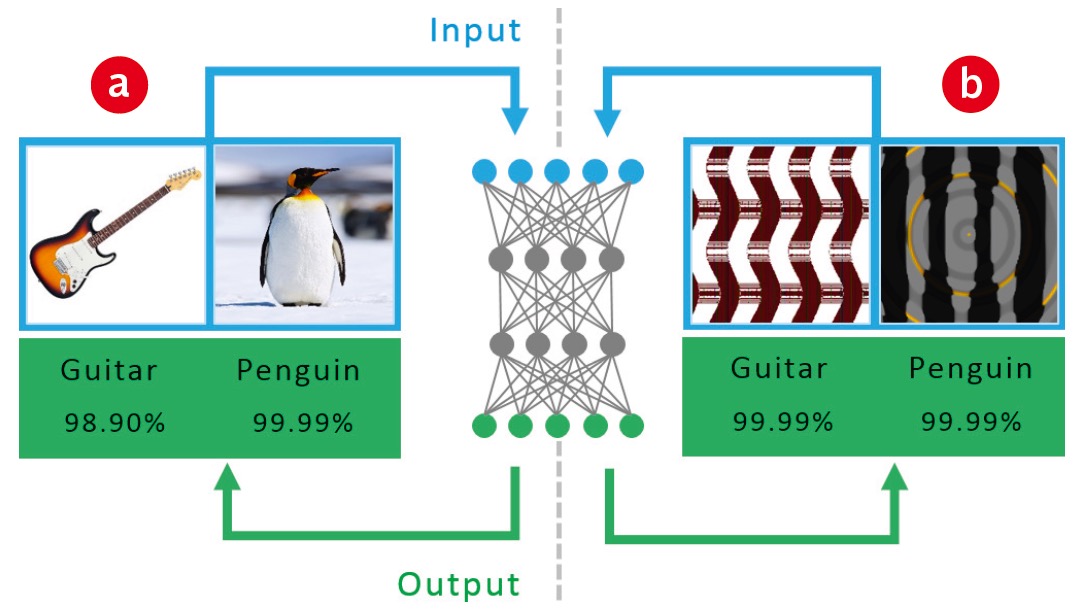
Bei Aufgaben wie einer Verschlagwortung von Fotos führt das zu Irritationen, etwa wenn eine Gesichtserkennung Gesichter oder gar bestimmte Personen zu erkennen meint, wo keine Menschen im Bild zu sehen sind. In Text-zu-Bild-Systemen fallen solche Fehlleistungen dagegen nicht auf, weil sie ihre Bilder mit einem Diffusion-Modell erzeugen, für den umgekehrten Weg von Koordinaten zu Bildern also ein anderes neuronales Netz als zur Bilderkennung verwenden.
[/registered_only]


Nicht immer präzise,aber brauchbar.
Schön, dass wir hier jetzt einen Profi haben, der es besser weiß als unser Autor. Seien Sie dann doch so nett und erklären uns, was präzisiert werden müsste. Besten Dank vorab!
Die generierten Bilder sind nicht immer präzise, aber brauchbar. Ich denke er meint die Bilder.